こんにちは。SRE の @int128 です。
AWS ではサービス単位(S3、RDS など)のコストは比較的簡単にモニタリングできますが、Pod 単位のコストとなると途端に難しくなります。 Amazon EKS のコスト管理について、多くの組織が同じような課題を抱えているのではないでしょうか。
今回は、AWS Cost and Usage Reports(CUR)の Split cost allocation data 機能を活用して、Pod 単位のコストを Datadog で日常的にモニタリングしている取り組みをご紹介します。
解決したい課題
Pod のコストが分かりにくい
スタディサプリのサービスは大部分が AWS で運用されています。 AWS のサービス単位のコストについては、AWS Budgets を Datadog に連携することで Datadog で日常的にモニタリングできるようになっています。 しかし、Amazon EKS にデプロイされている Pod については、コストが分かりにくいという課題がありました。
具体的には、以下のような課題がありました。
- サービスオーナーが Pod のコストを継続的に把握できない
- これまで Kubernetes のコストを可視化するツールである Kubecost が導入されており、Pod のコストを確認できるようになっていました。 しかし、Kubecost は操作が複雑で、無料バージョンではデータの保持期間に制限があるなどの課題がありました。
- 継続性を持たせるには、日常的に利用しているモニタリングツールの Datadog で確認したいというニーズがありました。
- SRE が Pod のコストを分析できない
- 定量的な議論が難しい
- Pod のコストに関する議論が発生した場合、実際のデータに基づいた議論ができず、机上の空論になりやすいという課題がありました。
理想的な状態
Pod 単位のコストを日常的にモニタリングできると、以下のメリットがあります。
- サービスオーナーが HPA やリソースなどを最適化して、コストを継続的に振り返ることができる
- SRE が毎月のコストチェックで EC2 の増減要因を分析する際に Pod のコストを活用できる
- 半期や年間の予算見積もりに Pod のコストを利用できる
解決策: CUR Split cost allocation data の活用
AWS Cost and Usage Reports(CUR)は、AWS の請求とコストの詳細情報を提供するサービスです。 その中でも Split cost allocation data という機能を使うと、EC2 インスタンスのコストを Pod のリソースリクエスト量に応じて配分できます。
コスト配分の仕組み
CUR の Split cost allocation data では、以下のロジックでコストが配分されます。
- リソースリクエストによる配分
- 未使用リソースの配分
例えば、CPU 4 コア、メモリ 16GB で時間単価 $52 という架空の EC2 インスタンスがあるとします。 この EC2 インスタンスのコストは以下のように配分されます。
- CPU 4 コアで $36(1 コアあたり $9)
- メモリ 16GB で $16(1GB あたり $1)
もし Pod が CPU 1 コア、メモリ 3GB をリクエストしている場合、その Pod には以下のコストが配分されます。
- リソースリクエストに基づく配分
- CPU コスト $9 × 1 コア = $9
- メモリコスト $1 × 3GB = $3
- 未使用リソースの配分
コスト配分の詳細は AWS のドキュメントを参照してください。
Split cost allocation data のデータ構造
AWS コンソールで新しい CUR を作成し、実際のデータ構造を確認してみましょう。 CUR では以下を設定します。
- 出力形式は CSV や Parquet などから選択できます。今回はツールでの集計を考慮して Parquet を選択します。
- Split cost allocation data を有効にします。
- Include resource IDs を有効にします。
しばらくすると、S3 バケットに CUR のデータが保存されます。 実際のデータを確認したところ、282 列が含まれていました。 CUR には Pod 以外のコストデータも含まれるため、Pod のコストに関連する行や列を抽出する必要があります。
Pod のコストに関連する主要な列は以下の通りです。
line_item_resource_id: Pod のリソース ID(形式:arn:aws:eks:REGION:ACCOUNT:pod/CLUSTER_NAME/NAMESPACE/POD_NAME/CONTAINER_ID)line_item_usage_type:APN1-EKS-EC2-vCPU-HoursまたはAPN1-EKS-EC2-GB-Hourssplit_line_item_split_cost: Pod に配分されたコストsplit_line_item_unused_cost: 未使用リソースの配分コストresource_tags_aws_eks_cluster_name: Pod が属する EKS クラスタの名前resource_tags_aws_eks_namespace: Pod が属する Namespace の名前resource_tags_aws_eks_deployment: Pod を識別するためのタグ情報resource_tags_aws_eks_workload_name: Pod を識別するためのタグ情報
集計単位の正規化
Pod のコストをどの単位で集計するかは重要な課題です。 サービスオーナーや SRE が実際にコストデータを活用するユースケースを整理することが重要です。 また、Kubernetes クラスタでは様々な Controller が Pod を管理していることを考慮する必要があります。
具体的には、以下のような要件を考慮する必要があります。
- サービスオーナーが認識しやすい(細かすぎない)
- SRE が要因分析で利用しやすい(粗すぎない)
- CronJob や Job の考慮
- DaemonSet や StatefulSet の考慮
- GitHub Actions runner や Argo Workflows などのカスタムリソースの考慮
最終的に、以下のクエリで集計単位を決定しています。 なお、Argo Workflows などのカスタムリソースではすべての Pod 名のパターンを網羅することが難しいため、概ね集計できれば良しとしています。
-- Extract POD_NAME from "arn:aws:eks:REGION:ACCOUNT:pod/CLUSTER_NAME/NAMESPACE/POD_NAME/CONTAINER_ID" CREATE OR REPLACE TEMPORARY MACRO extract_pod_name(line_item_resource_id) AS split_part(line_item_resource_id, '/', 4); SELECT -- 以下抜粋 CASE -- Deployment or Rollout WHEN resource_tags_aws_eks_deployment != '' THEN resource_tags_aws_eks_deployment -- DaemonSet or StatefulSet WHEN resource_tags_aws_eks_workload_type IN ('DaemonSet', 'StatefulSet') THEN resource_tags_aws_eks_workload_name -- ReplicaSet or Job WHEN resource_tags_aws_eks_workload_type != '' THEN regexp_replace(resource_tags_aws_eks_workload_name, '-\w+$', '') -- GitHub Actions WHEN resource_tags_aws_eks_namespace = 'arc-runners' THEN regexp_replace(extract_pod_name(line_item_resource_id), '-\w+-runner-.+$', '') WHEN resource_tags_aws_eks_namespace = 'arc-systems' THEN regexp_replace(extract_pod_name(line_item_resource_id), '-\w+-listener$', '') -- Argo Workflows WHEN resource_tags_aws_eks_namespace LIKE '%-workflow%' THEN regexp_replace(extract_pod_name(line_item_resource_id), '(-\w+-main)?-\d+.*$', '') ELSE extract_pod_name(line_item_resource_id) END AS workload_name, line_item_usage_type AS cost_usage_type FROM 'split-cost-allocation-data/*.parquet' WHERE resource_tags_aws_eks_cluster_name != '' AND resource_tags_aws_eks_namespace != '' AND split_line_item_split_cost > 0 GROUP BY resource_tags_aws_eks_cluster_name, resource_tags_aws_eks_namespace, resource_tags_aws_eks_workload_type, workload_name, line_item_usage_type ORDER BY cost DESC
データパイプラインの構築
S3 バケットに保存された CUR のデータを集計し、サービスオーナーが Datadog で確認できるようにすることが目標です。 継続性を確保するため、手動による集計ではなく自動化が必要です。
今回は GitHub Actions で以下のジョブを定期実行しています。
- S3 バケットから今月分の Parquet ファイルをダウンロードします。
- DuckDB で SQL を実行し、結果を CSV ファイルに保存します。
- send-datadog-action で CSV ファイルのデータを Datadog に送信します。
実際の活用事例
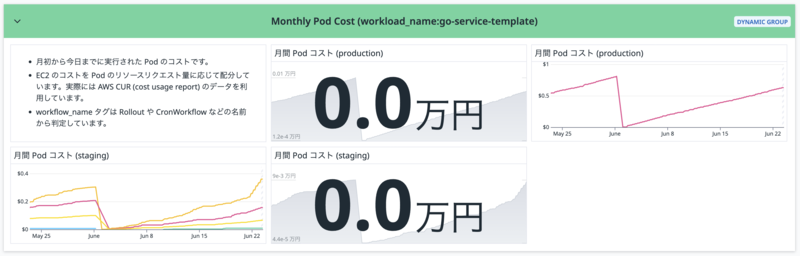
現在、Datadog で以下のメトリクスを利用できるようになっています。
- メトリクス名:
aws_eks_pod_monthly_cost - メトリクス値: 月初から今日までに実行された Pod のコスト
- 利用可能なタグ:
kube_cluster_name: クラスタ名kube_namespace: Namespace 名workload_name: Pod の集計単位workload_type: Pod のリソースの種類cost_usage_type: CPU コスト(apn1-eks-ec2-vcpu-hours)またはメモリコスト(apn1-eks-ec2-gb-hours)
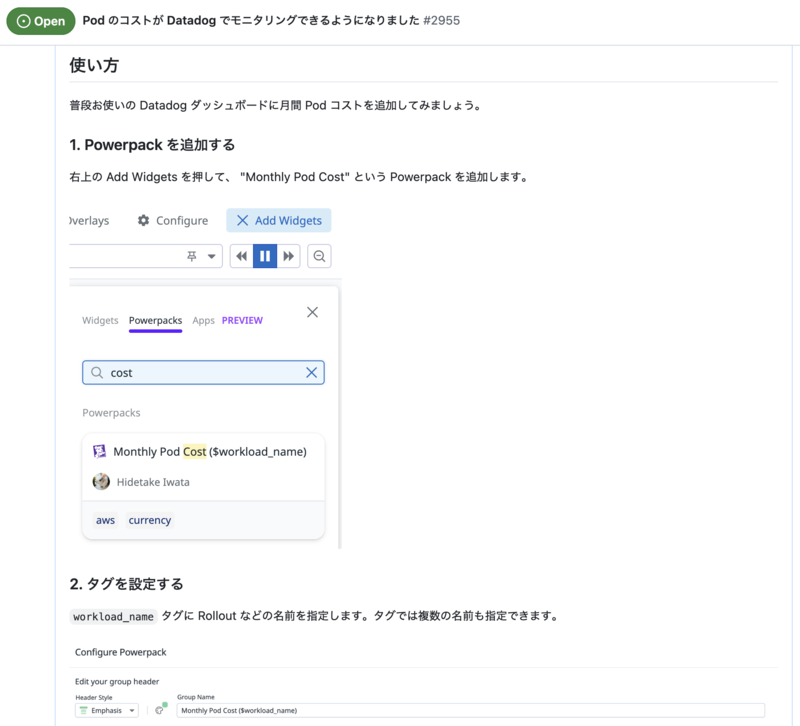
サービスオーナーが Datadog ダッシュボードに Pod コストを簡単に追加できるように Powerpack も用意しています。
注意点
Pod 間のコスト比較は避ける
CPU とメモリのリソース単価の比率(9:1)は AWS が決めた値であり、Pod 間の相対的なコスト効率を比較するには適していません。 例えば、以下のような Pod があるとします。
この場合、どちらの Pod が効率的であるかは一概に判断できません。 Pod が配置された EC2 インスタンスのタイプや未使用リソースの状況などにより、コスト効率は大きく変わる可能性があります。 そのため、Pod 間のコスト比較は避ける方がよいでしょう。
このメトリクスは自チームの Pod を長期的にモニタリングする用途で使用することを推奨します。
集計単位の制限
現在、AWS CUR のデータには Pod のラベルが含まれないため、Pod のラベルによる集計はできません。 例えば、Pod のラベルにはマイクロサービスの名前やオーナーチームが含まれるようにしていますが、そのような単位で集計できると更に便利になると考えています。
まとめ
AWS CUR の Split cost allocation data を活用することで、これまで課題となっていた Pod 単位のコストモニタリングを実現できました。 この取り組みによって、以下のような効果が得られています。
- 継続的なコスト監視: サービスオーナーが日常的に使用する Datadog で Pod のコストを確認できる
- 定量的な意思決定: リソース調整などの効果を数値で測定できる
同様の課題を抱えている組織の参考になれば幸いです。