こんにちは。SRE の近藤(@chaspy)です。
先日、より高い信頼性でサービスを提供するために、スタディサプリ小中高大のサービスの最後の砦であるデータベース、MongoDB のインスタンスクラスのスケールアップを行いました。また、スケールアップをするにあたり、負荷試験を行いました。
本記事では、データベースインスタンスのスケールアップの際に行なった負荷試験に対する考え方と、得た学びを紹介します。
なぜスケールアップするのか
サービスの急成長に伴い、アクセス数もデータ量も増加しています。数年前に「しばらくは大丈夫」と判断できるインスタンスクラスにスケールアップをしたデータベースも、高負荷時には性能が劣化してしまう問題に遭遇しました。
私たちの MongoDB は AWS 上に EC2 インスタンスとしてセルフホストしており、MongoDB Cloud Manager を使って運用の一部を自動化しています。可用性のために3台でクラスタを組んでおり、同じスペックの Primary / Secondary インスタンスと、読み書きされない待機用の Hidden Secondary で構成されています。
この構成では、一部の Read Query を Secondary に逃したとしても、(実際に、一部の Query は secondaryPrefered モードで動作しています)書き込みは Primary で行う必要があり、いつか I/O がボトルネックになってしまうことは明白です。
長期的には Data Restructuring Project による学習データの切り離し*1 による効果を期待していますが、それ以外に I/O の問題を解決するためには、シャーディングか、スケールアップしかありません。
水平方向のスケールであるシャーディングはシステムが今以上に複雑になってしまうことによるリスクがあること、また、負荷の軽減が急務であることから、今回は実績のあるスケールアップを行うことにしました。スケールアップする前は i3 という I/O に特化したインスタンスタイプでしたが、最近リリースされた、さらに I/O 性能が高い i3en タイプに変更することにしました。
しかし、本当にスケールアップで問題は解決するのでしょうか? Fact Based で考えるためには、負荷試験が必要です。
負荷試験用の環境
負荷試験はどのような環境を用意するべきでしょうか。また、どのように実施すべきでしょうか。
本番環境の状況を限りなく再現しようとすると、ウェブブラウザや iOS, Android といったネイティブアプリから実施することになりますが、現実と全く同じ規模の環境を用意することは現実的ではありません。また、試験をインターネットを介して行うことはコントロールできない部分が多くなり、結果が不安定になってしまうことが予想できます。そのため、テストを実施するクライアントはインターネットを介さない場所から実行する必要があります。
今回はできるだけ不安定な要素をなくすため、Staging の Kubernetes Cluster 上で、Database に直接読み書きを行う Backend のアプリケーションにリクエストを大量に送ることにしました。そのため、テストクライアントは同じ namespace の既存の Pod を利用しました。
Quipperでは アプリケーションプラットフォームにKubernetesを使うことにより、Pull-Request ごとに namespace を作成し、全アプリケーションが deploy される仕組みを構築しています。今回、負荷試験用にもこの環境を使いました。これによってステージングクラスタ上の他のリソースと分離してテストをすることができました。非常に便利ですね。
負荷試験環境を構築する際には、インターネットを介さないことの他に、以下のようなことを考慮するとよいでしょう。
- データベースは本番環境と同じスペック・クラスタ構成である
- データベースは本番環境と同じデータを所持している
- アプリケーションは本番環境と同じスペックである
- テスト環境は本番環境から分離されている
テストの実施方法と同じく、Computing Resource も本番を完全に再現することはコスト的にも現実的ではありません。可能な限りでやりましょう。
さぁ、これでテストの準備ができました。
負荷試験の目標
負荷試験用の環境はできました。さて、何を目標に負荷試験を行えばいいでしょうか。今回のような、スケールアップを見越した負荷試験は、理想的には以下の流れで行われるでしょう。
- 本番環境での性能劣化事象をテスト環境で再現する
- 1の再現条件で、本番環境と同一スペックのデータベースに対して benchmark を実施する
- 1の再現条件で、スケールアップしたスペックのデータベースに対して benchmark を実施する
2より3のほうが良い結果であれば、スケールアップは正しい選択であると言えます。逆に、スケールアップをしても問題が解消しない場合、今回予想している I/O あるいは他の Computing Resource 以外の部分がボトルネックになっていることになります。
しかし、これまでも述べたように、 1 の 本番環境での性能劣化事象を再現する ことは、近づけることはできても、完全に同じ状況を引き起こすことは不可能です。そもそも、何をもって「再現した」と言えるのでしょうか?私は負荷試験中かなり長い間この問いに向き合ってきました。
負荷試験の再現性を高めることは、SLO(可用性目標)のように、100% に近づければ近づけるほどコストが跳ね上がっていくのと同じ構造です。時間は有限なので、どこかで落とし所を見つける必要があります。
負荷試験をはじめた当初は、APM (NewRelic) で計測している Application の rpm (request per minutes) と MongoDB の平均レスポンスタイムを目標にしました。しかし、これらは試験を進めれば進めるほどに「本当にこの値が一致していたからといって本番と同一の事象が起きたと言えるのか?」という問いに苦しめられることになりました。詳しくは後述しますが、負荷試験を行うと大抵は様々なボトルネックに遭遇します。加えて、見るべき Metrics も対象システムを学ぶにつれて増えていきます。観測した Metrics の変化に因果関係を説明するには、対象システムの理解が必要です。
このような経験から、負荷試験の目標達成は、状況の完全な再現が困難であるため、不確実性が非常に高いと言えます。したがって、まず第一に仮説を立て、目標を設定することはもちろん大事ですが、いかに試行錯誤を繰り返せるかということがもっとも大事なことだと言えます。
テストプログラムの作成
さて、負荷試験を行うためにはプログラムによる自動化が必要です。もしかしたら curl でいいかもしれませんし、Apache Bench も選択肢にあがるかもしれません。
今回は、Read より Write の Query が支配的であることは APM によってわかっていたため、特定の API の、ある値を Update する Query を実行することにしました。
Google Chrome の DevTools では Copy as fetch という機能があり、これによって実行リクエストを JavaScript としてコピーできます。これを元に、後から簡単に調整できるように、実行多重数(LOADTEST_CONCURRENCY)、実行間隔(LOADTEST_INTERVAL)を環境変数に切り出し、for と setInterval によって一定の多重数で連続してリクエストを実行するテストプログラムを作成しました。以下のようなイメージです。
const fetch = require('node-fetch'); for (let i = 0; i < process.env.LOADTEST_CONCURRENCY; i++) { (function(n) { let cnt = 0; setInterval(() => { let foobar = { params: { something_foo: 1 something_var: 2 something_huga: 3 }, }; fetch("http://api/endpoint", { credentials: 'include', headers: { Authorization: process.env.ACCESS_TOKEN, }, body: JSON.stringify({ foobar: [{ ...foobar }], }), method: 'POST', }) .then(res => { console.log(`${Math.floor(new Date().getSeconds()) % 10}: ${res.status}`); return res.json(); }) .catch(err => { console.error(err); }); }, process.env.LOADTEST_INTERVAL); })(i); }
ボトルネックの解消
環境を構築し、(とりあえずの)目標も決め、テストプログラムもできました。あとはやるだけです。しかし、ただやるだけでは終わりません。前述したように、負荷試験は「ボトルネックの解消」との戦いと言っても過言ではありません。何かしらのボトルネックに達していなければ、それは負荷が不十分であると言えます。
この試験期間中、思い出すだけでも以下のようなボトルネックがありました。
- MongoDB の ストレージエンジン、WiredTiger の Write Ticket。これは同一の Object の Update Query を実施していたことが原因でした。対象の Object をユニークにすることで解消しました。
- Test Client の Computing Resource。大抵の負荷試験はまず最初がここにあたることが多いと思います。Pod をスケールさせました。
- Kubernetes の Controller Manager。Pod を大量に使用することによって、Controller Manager の負荷が上がり、OOM で殺されてしまいました。Resource Limit を増やすことで対処しました。また、単一の Pod で複数のリクエストを実行できるようにテストプログラムを変更しました。
- 開発環境と共有していた PostgresSQL の CPU 使用率。前述したように本来であれば最初から分離すべきでしたが、Helath Check でしか触らないので影響が小さいと考えていました。負荷試験用に新規構築しました。
このように、ボトルネックの解消を何度も何度も行うことになります。そのため、繰り返しますが、改善のサイクルをはやくまわすことが負荷試験においては非常に重要です。
また、ボトルネックの解消のためには、対象のシステムを理解していることが必要です。それがわからないと、ボトルネックが特定できませんし、再現したかどうかの判断もできません。
メトリクスの観察
本試験を行いながら、MongoDB の構成や Metrics について1から学びなおしました。MongoDB In Action という本を読んで全体的な仕組みを理解し、DatadogのDocument を参考に 負荷試験用の Dashboard を作成しました。
おもに見た Metrics は以下です。
- NewRelic
- rpm
- MongoDB respnse time
- DataDog
- System write kbyte per sec
- Wiredtiger available ticket
- system.io.await
- system.io.util
なぜこれらの Metrics を観察したのでしょうか。それを理解するために、アプリケーションが MongoDB へデータを読み書きするときの流れを考えてみましょう。
アプリケーションが MongoDB にデータを読み書きするとき、まず WiredTiger の Cache 領域にアクセスし、Cache に存在しない場合は Disk へ読み書きを行います。そのため、基本的には扱うデータのすべてが Memory 上に存在していることが望ましい状態です。
Disk へ読み書きする際、WiredTiger は Ticket という単位でファイルシステムへアクセスを行います。Read / Write それぞれ 128 が Available Ticket の最大です。Available Ticket が枯渇すれば、リクエストが来ても読み書きを行えません。
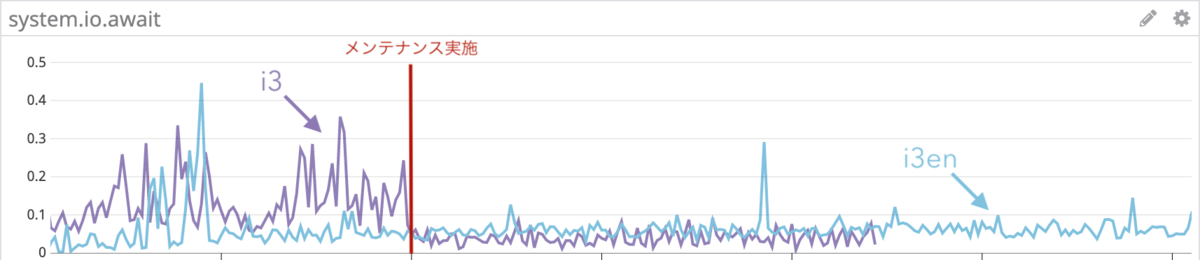
WiredTiger は Disk に書き込みを行うために、OS のシステムコールを呼びます。ここで system.io.await と system.io.util が登場します。もっとも重要な Metrics は system.io.await です。これは iostat*2 コマンドで取れる metrics と同じです。system.io.await は書き込み命令が待ち行列に並んで、実際に書き込みが完了するまでの時間のことです。この値が短ければ短いほど、I/O 性能が高いことを意味します。逆に、io.util はデバイスの使用率であり、write kbytes/sec も書き込んだデータの総量であるので、I/O の純粋な性能を測るには適していません。
よって、この負荷試験では、2つのインスタンスタイプで Benchmark を行い、i3 インスタンスタイプで I/O がボトルネックとなる負荷の条件で、i3en インスタンスタイプのほうが MongoDB response time が短く、io.await の値もより小さいことがゴールとなります。
負荷試験の結果
さて、ボトルネックを取り除いたことで、負荷試験の結果は想定通りになったでしょうか。答えは半分 Yes で、半分 No です。
負荷試験の目標をもう一度思い出しましょう。
1. 本番環境での性能劣化事象を再現する 2. 1の再現条件で、本番環境と同一スペックのデータベースに対して benchmark を実施する 3. 1の再現条件で、スケールアップしたスペックのデータベースに対して benchmark を実施する その結果、2より3のほうが良い結果が出るのであれば、スケールアップは正しい選択であると言えます。逆に、スケールアップをしても問題が解消しない場合、I/Oあるいは他のCompute Resource以外の部分がボトルネックになっていることになります。
今回、ボトルネックを可能な限り取り除いた状況で、現在の i3 インスタンスタイプと i3en のインスタンスタイプでそれぞれ benchmark をとったところ、i3en インスタンスタイプのほうがより高い負荷まで受け入れることができ、i3 インスタンスタイプで限界となっていた負荷でも性能が劣化しないことがわかりました。
しかし、そもそもの前提である 本番環境での性能劣化事象を再現する ができたとは言えないと考えています。*3
今回の検証では、i3 インスタンスタイプ で MongoDB のレスポンスが著しく劣化した条件で io.await も同様に劣化しており、i3en インスタンスタイプ では MongoDB のレスポンスも io.await も劣化していないことから、スケールアップが有効であることを結論付けました。
しかし、実際の本番環境で、MongoDB のレスポンスが劣化したときに必ずしも io.await が劣化していたわけではありませんでした(もちろん、劣化していたときもありました)。そのため、I/O 性能が原因で本番環境で MongoDB のレスポンスが劣化する事象が起きた、ということを断言することはできないと考えています。
とはいえ、同一の条件であればインスタンスのスケールアップが I/O の観点で有効であることが証明できたことは大きな成果です。また、今回のインスタンスタイプ変更で より上位のクラスを選択することにより、CPU、Memory のスペックも向上しており、I/O を含めた3つの要素でキャパシティが向上していることから、少なくともスケールアップをして効果が一切ない、あるいは逆に悪くなることはほぼありえないと考えました。
スケールアップを行った結果
先日のメンテナンスで無事にスケールアップを終え、Metrics を観察してみました。その結果、スケールアップの前後で io.await は格段に軽減しており、以前と同様のアプリケーションのスループットでも、以前より MongoDB のレスポンスは早くなっていることが分かりました。また、このメンテナンスの後、過去最大のスループットをアプリケーションで記録しましたが、問題が再現することなく、安定してサービスを提供することができました。
おわりに
今回、I/O 負荷によって MongoDB の性能劣化が発生したという問題に対して、インスタンスのスケールアップが本当に有効であるかどうかを負荷試験によって確認し、スケールアップが有効であることを示しました。
また、負荷試験を行う過程で、以下のことを学びました。
- 他のリソースへの影響を避けるため、可能な限り本番環境や既存のステージング環境と分離した環境を構築することが望ましい
- ボトルネックが移動するため、それを1つずつ取り除く必要がある
- 試行錯誤のサイクルをはやくまわすことがもっとも重要
- 試行錯誤する上で対象のシステムと関係する Metrics の理解が必要
また、MongoDB の Metrics を非常に多くの観点で把握できる DashBoard を得ることができました。
負荷試験そのものに対する考え方の他に、MongoDB そのものの理解と、Applicattion Platform である Kubernetes の 理解も深まり、非常に学びの多い経験でした。
負荷試験は対象システムの理解、モニタリング環境の整備、プログラムによるテストの自動化と、多くのことが要求されますが、このようなパフォーマンスの問題に対しての打ち手が有効かどうかを検証する場面に、本記事の考え方が参考になれば幸いです。
謝辞
この試験を行うにあたって、相談に乗っていただいた SRE チームのみなさん、ありがとうございました。特に最初に問題が発生したときに素早く Rate-Limit を実装してくれた @yuya-takeyama 、インスタンスクラスを変更する前にファイルシステムレベルでの benchmark を実施し、効果を確認してくれた上、さらに実際にインスタンスを入れ替えるオペレーションを綿密に準備してくれた @motobrew に心から感謝します。
Rate-Limitを実装する上で、Client からのリトライを実装してくれた Native チームの皆さんに心から感謝します。
最終的に MongoDB を入れ替えるためのメンテナンスを行うために関わってくれた Product Manager, Web Developer, Customer Support, Marketing Team を含むすべてのひとたちに心から感謝します。
Quipper では急成長するサービスの信頼性を守り、ユーザの皆さんが安心して使えるサービスを提供したい仲間を募集しています。
*1:学習データがデータ容量としても、書き込みの頻度としても高い
*2:iostat については 詳解システムパフォーマンス 9.6.1 iostat が詳しい
*3:完全な再現は不可能だとわかった上ですが