こんにちは、データエンジニアの@masaki925 です。
この記事はMLOps Advent Calendar 2020 の19 日目の記事です。
MLOps には、その成熟度に応じて3つのレベルがあると言われています。
- MLOps レベル 0: 手動プロセス
- MLOps レベル 1: ML パイプラインの自動化
- MLOps レベル 2: CI / CD パイプラインの自動化
私の所属するチームでは現在ここのレベルを上げるべく取り組んでいますが、その中でデータサイエンティスト(以下、DS) とデータエンジニア(以下、Dev) の協業って難しいよな〜と思う事例があったので紹介したいと思います。
想定読者は以下のような方です。
- これからMLOps を始めようとしている方
- 既存プロジェクトがあり、ML 等を使ってエンハンスしていきたいと考えている方
- 異文化協業に興味がある方
ML ワークフローではDS とDev がスムーズに協業する必要がある
冒頭で紹介した「MLOps レベル 0: 手動プロセス」では、ML ワークフローにはML とOps の境界線があるとしています。
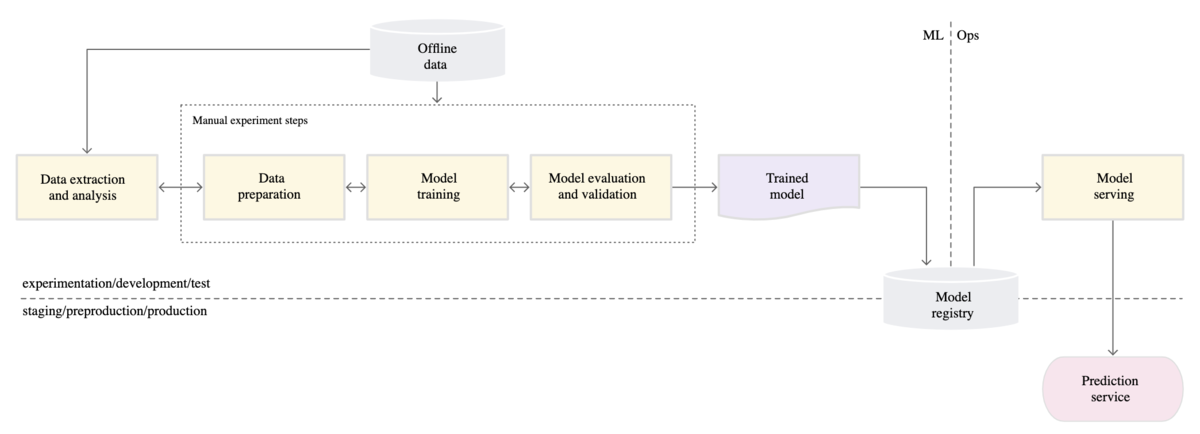
多少の差異はあれど、実際にはML はDS、Ops はDev が担当するというチーム構成はよくあると思います。
この段階ではこの境界に苦しむことはそんなに無いかもしれません。モデルの引き渡しはファイルの引き渡しに近く、インタフェース(以下、I/F) としてわかりやすいです。
レベル1 になると、全体像が膨らむと同時に、境界線の位置も変化します。
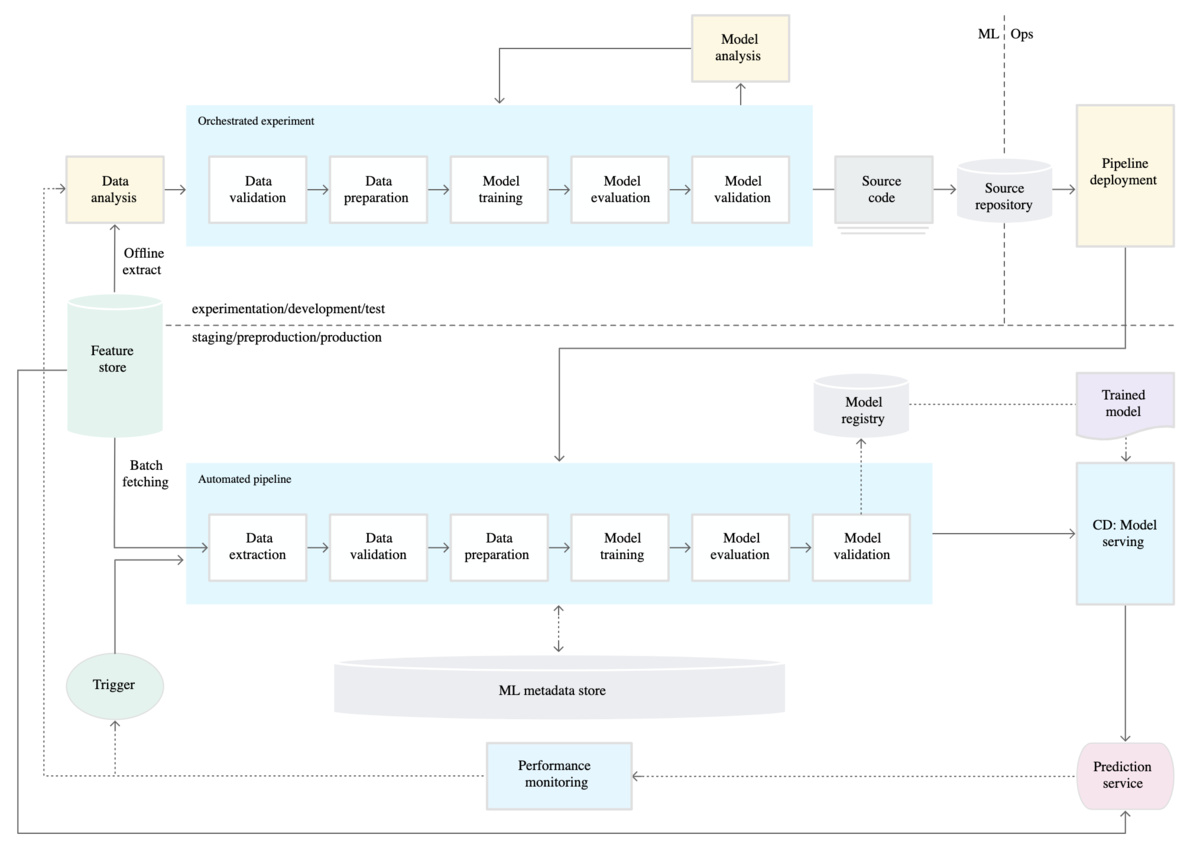
境界の部分に着目すると、ソースコードが境界となっています。
ここでは学習用プログラムが対象となりますが、 DS とDev が共通のコードベースを扱う ことになります。
一方、DS とDev には主に以下のような違いがあります。
- DS
- 関心事
- いかに精度高くモデルが組めるか
- ツール
- 実行環境: Anaconda, Jupiter Notebook など
- ML フレームワーク: TensorFlow, PyTorch など
- ライブラリ: NumPy, scikit-learn, pandas など
- DWH: BigQuery など
- 関心事
- Dev
異文化の交わるところに紛争あり。
ML ワークフローを整備していくにあたって、いかにDS とDev の協業をスムーズに行うことができるかは大事なポイントとなります。
以下、事例です。
既存レコメンドシステムへのMLワークフローの導入
案件概要
- レコメンドシステムのエンハンスとして、ML 機能およびワークフローを導入した
- チームとしてtoC 向けに提供するML ワークフローの導入は初
- 今後も汎用的に使えるML 基盤を構築したかったこと、また既に既存システムでBQ を利用していたことから、GCP が提供するMLOps サービスであるAI Platform を採用することとした
- 筆者がおおまかなアーキテクチャ・ワークフローの設計、別のメンバー(DS1名、Dev1名) が実装を担当 (ちなみに筆者は1:9 でDev 寄りです。)
ML ワークフロー レベル0.5
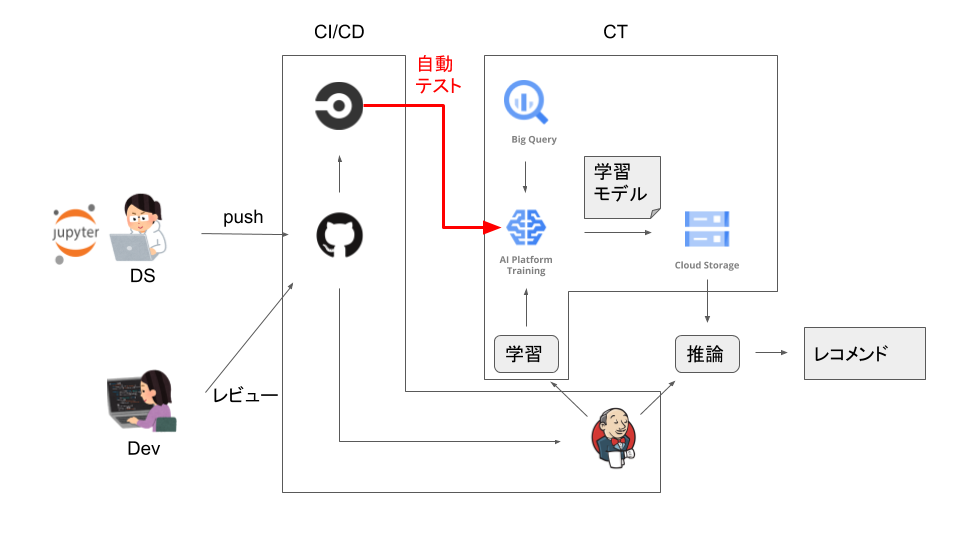
既存システムがGitHub, CircleCI, Jenkins を利用しており、そこにAI Platform を含むML パイプラインを追加した形です。
学習プログラムのCI/CD や継続的なモデル学習(CT, Continuous Training) が実施できている一方で、精度モニタリングやメタデータ管理などが整っていない分、レベルとしては0.5 くらいかなと筆者としては位置づけています。
赤字の自動テスト部分で、DS の書いたコードがAI Platform Training で問題なく動作することを担保しています。
もう少し詳しく見ていきます。
協業部分のI/F 詳細 (当初案)
具体的なDS とDev のI/F 定義は、どのコードのどの部分をどちらが管理するか、を定義することになります。
学習プログラム全体としては以下のような構成です。

当初案では、点線で区切ったラインをI/F とすることにしました。
ワークフロー図と合わせて手順を書き起こすとこんなかんじです。
- [Dev] 最低限のjob が走るところまでの雛形(点線の上部分) をDev 側で用意
- [DS] R&D on Notebook (ここでは雛形は気にしない)
- [DS] Notebook からtask.py やsql ファイル群(点線の下部分) に移植
- [DS] git push (branch)
- (CI)
- CI にてAI Platform Trainig job をsubmit
- 成功すればOK。失敗すればDS がコードを修正。
- => DS が書いたコードが問題なく動作することを担保
- [Dev] レビュー & approve
- [DS] merge
CI では下記のコマンドでAI Platform Training にjob がsubmit されます。

これにより、以下のような並列作業が実現できると考えました。
- DS はモデルの検証やチューニングに注力でき、自由に学習コードが変更できる
- Dev はDS の変更に引きずられることなく、パイプラインの運用やレコメンドを受け取った後のアプリケーション部分の開発に注力できる
が、蓋を開けてみると想定したとおりには進みませんでした。
甘かったI/F 定義
大きく2つの問題がありました。
DS の検証用コードをそのままパイプラインに持っていっても動かない
当たり前ですが。
以下のような理由により、Notebook のコードをそのままパイプラインに乗せてもうまく動きませんでした。
問題が顕在化したときには既にDS とDev は並列作業しており、DS は精度検証などで余力が無かったため、Dev が修正(パイプライン化) をすることになりました。
その際、検証コードはあまり構造化(メソッド定義やモジュール化) がされておらず(検証の段階では不要なため当然といえば当然)、可読性や保守性に難があったため、それらも合わせて実施することになりました。
Dev としては修正する対象が普段利用するツールではないため、ここの書き換えには学習コストが発生しました。
DS とDev 間でコードの二重管理が発生
前述のとおり、当初DS が管理するはずだったtask.py は、実際にはDev が管理する状況になっていました。
一方、DS の検証作業も並列作業中だったこともあり、検証コードにも随時変更が入る状況。
DS は検証コード用のPR, Dev はパイプライン化したコードのPR をそれぞれ別々に扱う状況になってしまっていました。

納期が迫る中で、DS がパイプライン化コードの学習コストを払うよりも、Dev に都度依頼するという「運用でカバー」という状態になっていました。
辛い。
いいこともあった
意図せずDev が学習用コードを細かく見る必要が出たため、その過程で冗長なクエリに気付き、モデル学習にかかる時間が改善したということがありました。
学習時間が長すぎることにより、対象となるログやユーザーの数を制限する案も出ていたため、プロダクト品質的にも助かりました。
そんなこんなで、当初の予定からやや遅延しつつも、無事に機能をリリースすることができ、初速では良いKPI 数値が出ていることも確認できました。
「検証コードのパイプライン化」を協業タスク化しよう
今回の問題への対応はシンプルに「検証コードをパイプライン化した後は、パイプライン化コードを更新する」となるでしょう。
ただ、なぜそれが今回できなかったか?
当初案では、管理するコードを明確に分離することで境界線を設け、互いに独立して作業ができることを狙いました。
しかし実際には、検証コードをパイプライン化する必要があり、そのためには以下のようなタスクが伴いました。
- input, output など外部接続が伴う処理を、パイプラインが利用するDWH, ストレージに対応させる
- コードを構造化(ベタ書きのSQL を別ファイルに分けてレビューしやすくする、なども含む) して保守しやすくする
- 検証コード内で非効率な処理があれば改善する
その過程で、DS はDev の領域のキャッチアップが必要だったり、その逆もまた然りでした。
これらは(各個人の能力にも依りますが) どちらか一方のスキルセットだけで完結させるのはハードルが高い場合があるため、あらかじめ協業する部分と捉えて、お互いの作業しやすい部分が見えてから各自の作業に分かれるのがよいと思います。
レベル上げは続く
今回はチームで初めてML ワークフローを組み込んだということもあり、 既存システムの一部に組み込む形でAI Platform Training を利用してMLOps を小さく始められたことは良かったと思っています。
レベル2 までの道のりはまだ遠く感じられますが、より高いレベルでのMLOps にも取り組んでいきたいです。
その中ではおそらくまたDS とDev が交わる部分も出てくると思いますが、
境界部分には予め協業タスクを積んでおくことで、今回のような「運用でカバー」的な対応がなるべく生まれないように気をつけていきたいと思います。
みなさんの中でも同じような問題意識を持っていたり、うまく回っている事例などがあれば、ぜひ教えていただけるとうれしいです。