はじめまして、webエンジニアの@shushutochakoと@yoh-shimizuです。普段はスタディサプリ学校向けの事業でwebフロント&サーバサイドの開発をしています。
学校向けの事業では『スタディサプリ for TEACHERS』と言う先生向けのプロダクトがあり、先生が生徒に宿題を配信する機能があります。 宿題配信機能はサービスの中でも核となる機能で、多い月では数万件以上の宿題が配信されます。
サービスの中で重要な機能であるため、その基盤の安定性は極めて重要です。配信処理が不安定である場合に重大なインシデントが発生するリスクがあるため、日々改善に向けた取り組みが求められます。
既存の配信基盤は安定性に関していくつか課題を抱えており、この度新しい基盤への移行を進めることに決定しました。
今回は私たちのチームがどのような過程を経て移行を実現したのか、その詳細をご紹介したいと思います。
宿題配信について
移行の話をする前に宿題配信機能について少し触れたいと思います。
スタディサプリでは先生が画面上から宿題を配信をすることができます。 配信する際は主に以下のような設定をします。
- 宿題のタイトル
- 宿題に含む動画やテスト問題
- 配信期間
このような配信機能以外にも『スタディサプリ for TEACHERS』では色々なタイミングで宿題が配信されます。 例えば以下のようなパターンでも宿題を配信します。
etc. 他にも色々あります
このような背景もあり、宿題の配信システムは日々複雑化していきました。
移行の背景
ここから移行について書きたいと思います。
まずは、旧基盤ではどのような問題を抱えていて、それを解決するために新基盤をどのような構成にしたのかについてお話しします。
旧基盤の課題
旧基盤を図にするとおおまかに以下のような構成になっています。
※かなり簡略化しています
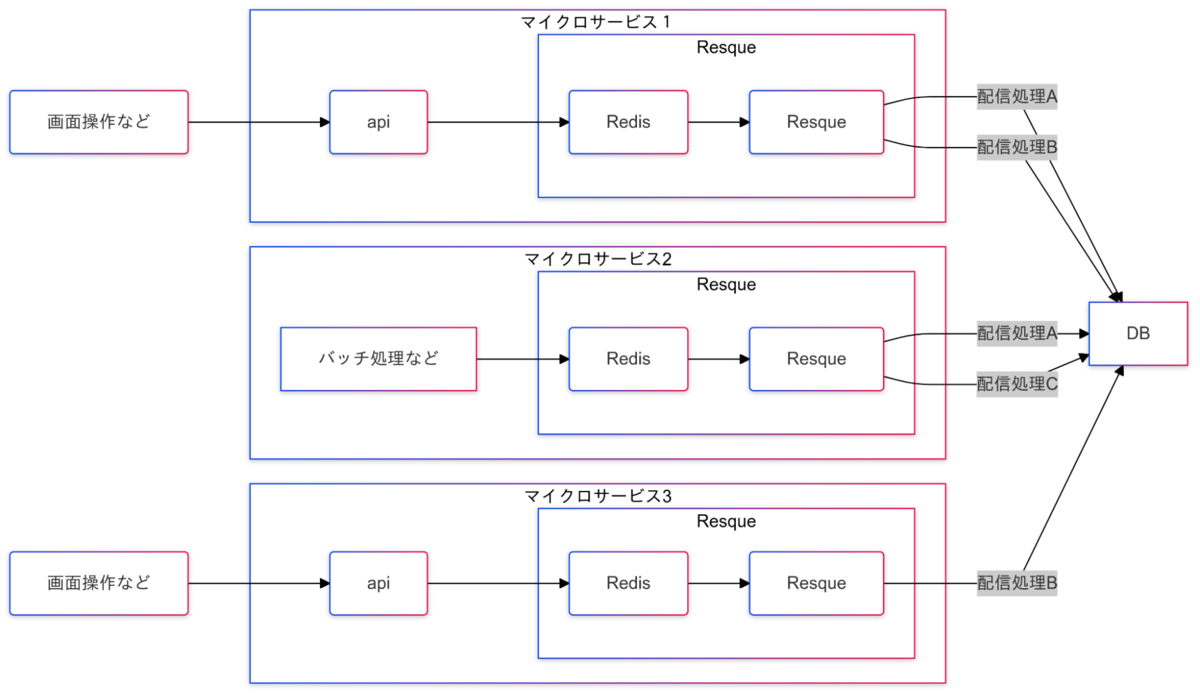
旧基盤には以下の課題が存在しており、特に障害発生時や問い合わせが発生した際に顕著に表れます。これらの課題はいずれも保守工数の増大につながる要因となっていました。
1. ジョブの消失
スタディサプリではResqueジョブのリトライ機構をresque-retryというプラグインで実現しています。 resque-retryの仕組み上、ジョブの実行が開始した後にアプリケーション環境のハングアップなどにより適切にリトライされずジョブが消失するといった問題を抱えていました。
このような問題を解消し、確実にリトライ機構が機能する基盤の構築が求められていました。
2. 認知負荷が高い
先ほど書いた配信パターンの違いや同じパターンでも処理タイミングの違いにより、様々なサービスで宿題配信処理を実行しています。
現状は各サービスは配信するためのResque機構をそれぞれで管理している状況であり、どのサービスで何の処理が実行されているのかを理解することが困難になっていました。
3. モニタリングし辛い
宿題の配信処理は多少時間がかかること自体は想定しており、非同期処理となっています。 しかし、大幅な遅延が発生すると先生の業務や生徒の学習体験に悪影響を及ぼす可能性があります。
これまで、Resqueジョブのトラッキングを自前で構築するなどの試みを行ってきましたが、期待通りにトラッキングができないなどモニタリングに対する懸念がありました。 また、上述の通り色々な箇所で配信の実行環境を持っていたので各所でモニタリングの設定が必要など保守効率を下げる要因となっていました。
新基盤の構成
旧基盤の課題をふまえ新基盤は以下のような構成にしました。
※こちらも簡略化しています
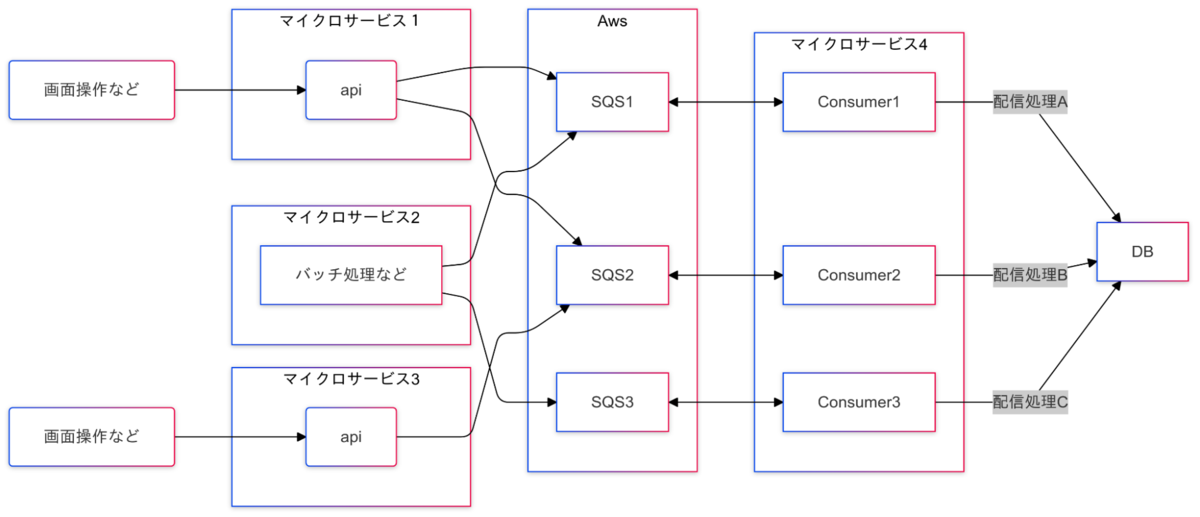
新しい基盤では実際の配信処理を担うのはマイクロサービス4のみとなりました。マイクロサービス1〜3はAmazon SQSへメッセージを送信するところまでが役割です。
旧基盤の各課題がどうなったか見てみましょう。
1.ジョブの消失
Amazon SQSではQueueからメッセージを明示的に削除しない限りはタスクが消えることはありません。これにより予期せぬアプリケーションプロセスのハングアップなどが起きてもジョブが消失する危険性はなくなりました。
2.認知負荷が高い
各マイクロサービスでは独自に配信機構を持つ必要が無くなり、配信に関する処理や設定などの諸々をマイクロサービス4に集約する事ができました。配信処理の具体的な内容についてはマイクロサービス4を見るだけで把握する事が可能です。
3.モニタリングし辛い
Amazon SQSでは「Age Of Oldest Message(一番長命のメッセージの滞在時間)」などの便利な指標をCloudWatch metrics経由で取得できます。そのため色々な独自機構を実装する必要なく配信遅延のモニタリングなどが可能になります。 また、Amazon SQSやマイクロサービス4をモニタリングすれば状況の把握が可能なため、色々な箇所でモニタリングする必要も無くなりました。
移行の計画・実施
旧基盤から新基盤への移行について、どのように計画し、実施したのかをお話していきます。
1.課題の整理
まずは、旧基盤が抱える課題を明確にしました。 先述した旧基盤と新基盤の比較はこの作業の成果です。 この取り組みは単なる問題の洗い出しではなく、チーム全体の共通理解を深める重要なプロセスです。
新しい基盤・技術を取り入れる際によく起こり得ることとして、「置き換える・取り入れることが目的になってしまう」ことがあります。新しくモダンな技術を取り入れることはとてもワクワクします。 しかし、今回のような課題が背景にある中で「〇〇を使うことですべて解決するのでは?」と漠然としたイメージで移行を遂行した場合、課題解決できず工数が無駄になってしまいます。 (この現象は「十分に課題を整理しないまま新しいホットな技術情報を見つけた際によく起こるのかな」と想像しています)
多くのメンバーが頭の中で感じている問題はあれど、具体的には文書化されておらず腰が重い状況が続いていました。そこで、まず各々が認識している既存基盤での課題を整理し、議論の出発点とすることにしました。 この作業を通じて私たちは
- 複雑な宿題配信処理の理解を深めることができた
- 新たに浮かび上がる課題に気づくことができた
と非常に有意義な時間を過ごすことができ、移行に向けた一歩を踏み出すことができました。
2.移行計画の策定
配信パターン毎の移行タイミングの整理
「旧基盤」から「新基盤」に移行が決定したからといって、一気に全て移行することのリスクはとても大きいものです。 宿題機能はたくさんの先生・生徒の皆さんにお使いいただいており、移行により既存の機能が使えなくなった場合多大なご迷惑をおかけしてしまいます。このリスクを減らすために、最初は影響が小さい規模から移行を行っていき、最終的に全て置き換えるアプローチを取りました。 では、段階的に移行をするとして、どのような区切り方で移行をするのでしょうか?
「宿題配信について」で書いたとおり、宿題配信には色々なパターンがあります。
- クラスの生徒に先生が宿題を配信する
- 生徒AをクラスBに所属させる
- クラスBの生徒に既に配信されている宿題を生徒Aに対して後追いで配信する
- ある宿題を完了した際に理解度に応じて新しい宿題を自動で配信する
etc.
その中でも「メインの配信機能ではない」「負荷のピーク時期が移行タイミングと重ならない」ことを考慮し、2を最初の移行対象に決めました。
さらに複雑なのが、パターン2の中でも同じ処理内容が複数箇所で実行されているということがある点です。
こちらも全箇所一気に置き換えるのではなく1箇所ずつ置き換えることでより安全に移行するようにしました。
問題発生時の考慮
どれだけ対策を講じても、何かしらの問題が発生する可能性があります。 仮に問題が発生した場合でも、「影響を最小限に抑える」ことや「問題のない状態へ迅速に復旧する」ための準備をしておくことが重要です。
当ブログをご覧いただいてる方はご存知かもしれませんが、スタディサプリではDarklaunchと呼ばれるFeature toggles 機構が存在します。
この機構を活用することで、「一部のユーザーにだけ機能を開放する」ことや、「新基盤での配信をオフにして既存の基盤による配信処理へすぐに戻す」ことが可能となりました。
この対策によりリスクを低く保ちながら移行を実施することができました。
3.非機能要件の整理・負荷テスト
今回の移行プロジェクトで一番重かったテーマがこちらです。
「既存基盤での課題を整理できた」「移行計画もできた」ということで、「よし、プロトタイプを作って色々試していたけれど本格的にインフラの立ち上げ・プログラムの修正をして移行していくぞ!」と進めてきましたが、もう1つ大事な工程があります。
それは、「非機能要件の整理」です。大多数の配信処理が同時に実行された際に「consumerはqueueに溜まるメッセージを詰まり無く処理できるのか」「consumerにとって適切なCPU・メモリなどの設定はどれか」などパフォーマンスに関連する非機能要件の検討が必要です。
アーキテクチャの変更(特にResqueからAmazon SQSへの変更など)によってパフォーマンス要件にどのように影響するかが懸念されました。
パフォーマンスの基準の設定
機能をリリースするにあたって、クリアするパフォーマンスのひとつの基準としてSLO(Service Level Objective)があります。施策実施時点で宿題の配信処理に関してはSLOが定められておらず、関係者とどの程度のパフォーマンスレベルで合意を得るべきかが課題となっていました。最終的には、「現状のパフォーマンスを維持する」という基準でパフォーマンスを維持することを決定しました。
現状のパフォーマンスの調査
「現状のパフォーマンスを維持する」という目標を設定したものの、その具体的な指標を明確にするにはさらなる分析が必要でした。 「今のシステムと同じ感じで、処理の速さとかいい感じで!!」と何となく分かっても「何がどうなっていれば今のパフォーマンスと同じと言えるのか」つまり実際の現状のパフォーマンスがどの程度かを理解していなかったためです。 そのため、過去1年間のログデータを徹底的に調査しました。
調査内容の例
- 1つの宿題に含まれる講義の数
- 生徒1人あたりの平均宿題数
- 配信開始から配信完了までの時間
調査した結果から「負荷の掛け方」「達成すべきパフォーマンス」を整理し、負荷テストのクリア条件を設定することができました。
負荷試験を含めた非機能要件に関連するこれらのプロセスは、今回の移行作業の中で最も時間と労力を要した部分です。
地道な作業であり、「大丈夫なんじゃないかな?とりあえずリリースしてみても良いんじゃないかな?」と楽をしたい気持ちに逃げたくなる時もありました。
しかし、移行によって保守効率が上がるとはいえ配信の速度が落ちてユーザビリティを下げることは絶対に避けなければなりません。
必要なプロセスをスキップしたことで、アプリケーションが期待通りに動作せず、サービスを利用する先生や生徒の皆さんが悲しい思いをする姿を想像しました。その結果、「やるべきだ、やらなければならない」と考え直し、計画と実施に全力で取り組みました。
関係者との合意、そしてリリース
負荷テストが全て完了し移行の準備がある程度進んだ段階で、関係者と最終合意しました。 以下の内容がまとまったリリース判定ドキュメントを作成します。
- 基盤移行の概要
- 機能テスト詳細
- 正常系・異常系で期待される結果とテスト結果
- 非機能テスト詳細
- パフォーマンス基準
- 検証内容
- 負荷テストの方法・結果
- 移行計画
- どのように段階的に移行していくのか
作成したドキュメントを@shushutochako @yoh-shimizuをはじめとしたdeveloperチーム、Managerなどプロダクトの関係者を中心としたメンバーでレビューをし、内容に問題がないことを確認しリリースの合意をしました。
すべて完了したあと、本番環境へリリースしました。 最初は宿題機能をたくさん利用してくださっている数団体のユーザーさんの環境でのみ移行を実施させていただき、その後タイミングを見ながら最終的に全ユーザーに向けて移行を完了しました。 初回リリース〜全ユーザーへの機能開放まで大きな障害無く、無事遂行することができました。
まとめ
以上が宿題配信基盤移行についての流れです。
・
・
・
と、まるで宿題配信基盤移行が全て完了したかのようにお話させていただきましたが、今回移行したのは全宿題配信導線の中でも小さな一導線のみです。
この後にはより複雑なパターンやメインとなる宿題配信導線という大ボスが控えており、まだまだ宿題配信基盤移行の戦いは始まったばかりです。
しかし、私達は今回の移行経験によって必要なタスクを改めて認識することができ、今後より確度の高い計画ができると考えています。
大きな負債解消プロジェクトの第一歩を踏み出せた今、最後まで走りきりたいと思います。