こんにちは、データエンジニアの @masaki925 です。
今年の春リニューアルされたスタディサプリの中学講座にて、レコメンドシステムを新規構築しました。
そのアーキテクチャが、当初意図していなかったものの、結果的にはCQRS (Command Query Responsibility Segregation) パターンと呼べるものになっていました。
本記事では、CQRS の特徴に則って当該アーキテクチャを紹介しつつ、今後に向けて考察します。
- CQRS パターン + イベントソーシング
- なぜCQRS + イベントソーシングか
- アーキテクチャ
- 「CQRS の利点」との比較
- 「CQRS の課題」との比較
- 「イベントソーシングとの組み合わせ」に関して
- その他所感
- まとめ
CQRS パターン + イベントソーシング
各パターンについてはAzure Architecture Center の記事がよくまとまっています。
イベントソーシングパターンはCQRS と用いられることが多いとされており、今回も該当したため合わせて触れておきます。
CQRS パターン - Azure Architecture Center
CQRS はコマンド クエリ責務分離を表し、データ ストアの読み取りと更新の操作を分離するパターンです。
イベント ソーシング パターン - Azure Architecture Center
ドメインに、データの現在の状態だけを格納する代わりに、追加専用ストアを使用して、そのデータに対して実行された一連のすべてのアクションを記録します。
なぜCQRS + イベントソーシングか
案件としては、学習ログを元に次に学習すべきコンテンツをレコメンドするというものでした。
スタディサプリではリニューアル以前から同様のレコメンド機能があります*1 が、これはバッチ処理で生成されたレコメンドリストをAPI 経由で返すだけの、いわばread only なAPI でした。
今回追加された要件としては、以下がありました。
1. 分析用の学習ログと、レコメンドシステム用の学習ログは分けたい
従来同様、レコメンドシステムはスタディサプリの本体から提供される学習ログを利用し、レコメンドを提供するというマイクロサービスです。
今回レコメンドがよりUX にとって重要度が増していることもあり、本体側でのデータスキーマの変更によるレコメンドシステムへの影響範囲を限定できるよう、従来の分析用ログよりも内容を絞り込んだ学習ログを利用することになりました。
分析用のログはデータ基盤チームでデータウェアハウスとして管理されていますが、それとは別の管理が必要となりました。
2. 直前の学習状況をリアルタイムに反映したレコメンドをしたい
いわゆるリアルタイム推論のようなことをする必要があり、バッチでは要件を満たせませんでした。
実はこの機能は初期リリースでは諸都合により延期になりましたが、アーキテクチャレベルでは実現可能となるようにしています。
3. レコメンドロジックはルールベースで開始し、ログが溜まったのちに機械学習(ML) ベースに移行したい
リリース当初は学習ログからルール実装によってレコメンドを生成する必要がありました。
移行の際に可能な限りアーキテクチャレベルでの変更が発生しないようにしました。
4. 学習ログはスナップショットではなく、時系列を保持する
様々なレコメンドロジックに柔軟に対応するため、より多くの情報を記録したいという意図がありました。
ざっくりまとめると、レコメンド用の学習ログを適切に保存する機能と、それをリアルタイムに参照する機能が必要でした。 また将来的なML 移行に備え、ML 処理そのものが孕む複雑性とログの書き込み処理を分離したいというモチベーションがありました。
以上のことから、CQRS とイベントソーシングを組み合わせたアーキテクチャを採用することにしました。
プラットフォームは、データウェアハウスとの兼ね合いやメンバーの得意領域を加味して、GCP を選択しています。
アーキテクチャ
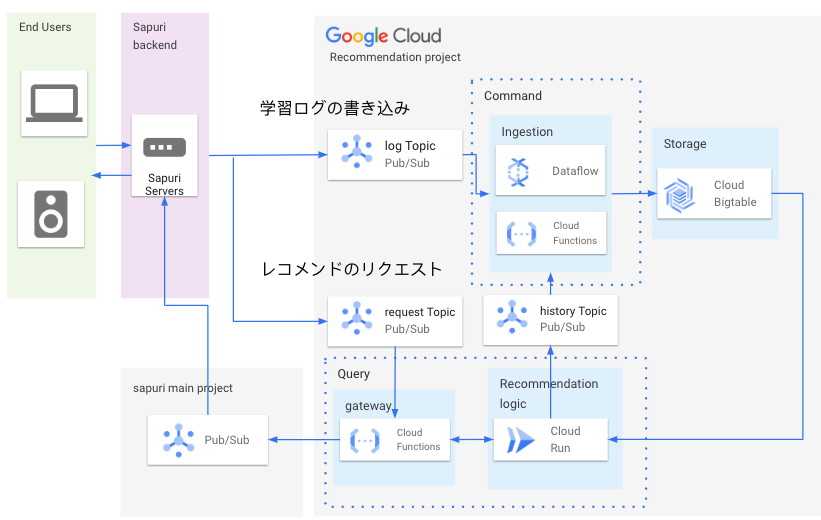
補足
- Command, Query にあたる部分をそれぞれ点線で括っています。
- Ingestion のCloud Function はDataflow に一部移行中です (後述)
- レコメンドのリクエストもPub/Sub インタフェースに寄せています。これはML 処理が多少遅延してもよいように、あらかじめ非同期処理化したことによるものです。UI 側ではローディングアニメーションなどで遅延を想定した作りにしてもらっています。
- レコメンド生成ロジックからも書き込み処理が発生しています。これは、レコメンド生成ログもレコメンドそのものに影響するためです。Bigtable への書き込み処理をCommand 部分に集約するため、Pub/Sub を経由するようにしました。
- 現状、レコメンドリクエストはユーザーの学習とは異なる特定の行動をトリガーとして送られています。
- 前述の通り、リアルタイム推論は図にありませんが、実装する際にはlog Topic をトリガーとして、学習ログの保存したうえでCloud Run などのレコメンド生成ロジックを呼び出して本体に戻す構成にすれば要件を満たせる想定です。
以下、冒頭に紹介した記事 に沿ってCQRS パターンの特徴と今回のアーキテクチャを比較していきます。
「CQRS の利点」との比較
独立したスケーリング
CQRS では、読み取りと書き込みの各ワークロードを個別にスケーリングできるので、ロック競合を減らせる可能性があります。
今回はログの追記がメインでトランザクションなども考慮しなかったため、ロック競合については該当しませんでしたが、
ワークロードに関しては、書き込みのほうが多くて平均で約40倍、ピーク時で3倍程度の差がありました。(リクエスト数ベース)
それに伴い、それぞれのCloud Function やCloud Run のMin Instance などの設定が個別に調整できています。
また、当初実装の容易さからCloud Function のpush 方式で実装した書き込み側を、スケーラビリティの観点から徐々にDataflow のpull 方式への置き換えが進んでおり、システムのリプレイスが限定的に行えることも双方が独立していることのメリットに感じています。
最適化されたデータ スキーマ
こちらは現状は該当しませんでしたが、 将来的にML ベースに移行した際には、読み取り側は実質Feature Store のように整形済みの特徴量を保持することが考えられ、そうなるとこのメリットが活きてくるかもしれません。
ただそうなると結局、特徴量生成システムが両方のデータスキーマを把握する必要があるため、それぞれの同期をいかにスマートに実現できるかは課題となりそうです。
セキュリティ
適切なドメイン エンティティだけがデータへの書き込みを実行している状態を維持しやすくなります。
今回は双方でデータモデルを共有しており、実際には読み取り側にあるモデルクラスも更新メソッドを持っています。
これはこれでユニットテスト用にデータを事前に書き込むために利用したりしていますが、
テストにはBigtable emulator を利用しているため、実際のサービスにアクセスする権限は不要でした。
読み取り側のService Account にはread only な権限 のみを付与することで、意図しない更新を防ぐことができそうです。
懸念事項の分離
読み取り側と書き込み側を分離することで、モデルの保守性と柔軟性を向上できる可能性があります。 複雑なビジネス ロジックの多くは、書き込みモデルになります。 読み取りモデルは、比較的シンプルにすることができます。
ここにある通り、書き込み側と読み込み側でそれぞれコードベースをシンプルにすることができました。
書き込み側ではデータロストに備えたバックアップ・リストアの仕組みを構築する必要がありましたが、 読み込み側ではそのあたりの複雑性をほぼ気にすることなく、ロジックの実装に集中できました。
クエリがよりシンプル
具体化されたビューを読み取りデータベースに格納することで、クエリ時の複雑な結合を回避できます。
前述の通り現状はデータモデルは共通なため、泥臭くDataFrame に落とし込んでロジックでこねくり回すような実装になっています。
Feature Store を採用した場合には、ここの処理が、少なくとも読み取り側ではシンプルになるはずです。
どのみち特徴量に変換する際には結局同じ複雑性が発生するはずですが、懸念事項が分離できていることで保守しやすくなる可能性はあります。
「CQRS の課題」との比較
複雑さ
CQRS の基本的な考え方はシンプルです。 ただし、アプリケーションの設計は複雑になる可能性があります。このことは、イベント ソーシング パターンが含まれる場合には特に顕著です。
これはアーキテクチャ図を見てもわかるように、単純なCRUD な構成と比べてコンポーネントの数が増えており、その点で複雑になっていると言えます。
各コンポーネントでのエラーハンドリングを想定する必要があり、ロギングやモニタリングも見る箇所が増えます。
Pub/Sub のdead letter, Replay を活用したエラーハンドリングには学習コストが必要でしたが、
一度習得してしまえば、各コンポーネントはTerraform の定義をコピーしていくだけなので、そこまで見通しが悪くなることもありませんでした。
ただ、エラー時に各所に散らばったエラーを漁って、周辺時刻での状況を把握する作業はまだ複数のステップが必要な状況で、このあたりは改善の余地がありそうです。
メッセージング
CQRS ではメッセージングは必須ではありませんが、コマンドの発行やイベントの更新を処理するためにメッセージングが使用されることもよくあります。 その場合には、メッセージのエラーや重複を処理する必要が生じます。 優先度の異なるコマンドを処理するための優先キューに関するガイダンスを参照してください。
今回はあまり該当しなかったのですが、
エラーハンドリング(Pub/Sub Replay など) で発生する重複処理についてはBigtable のRow Key を冪等に設計するよう気をつけました。
難しい点として、アプリケーションエラーなどで学習ログが誤って保存されてしまった場合に、誤った学習ログを元に生成されたレコメンドの生成ログや、それが既にユーザーの目に触れてしまった場合にどこまでを修正すべきかという点がありましたが、
影響範囲が限られることや発生頻度がかなり低いことなどから、その場合は学習ログの修正までに留めています。
最終的な一貫性
読み取りデータベースと書き込みデータベースを分割すると、読み取りデータが古くなる可能性があります。 読み取りモデル ストアは、書き込みモデル ストアへの変更を反映させるために更新する必要がありますが、ユーザーが古い読み取りデータに基づいた要求をいつ発行したのかを検出するのは容易でない場合があります。
確かに学習ログが保存されたタイミングからレコメンドを生成するまでのタイムラグは気にする必要がありましたが、現状数十〜百msec に収まっており、学習から次のレコメンドが表示されるまでの間の時間としては十分な猶予があるため、問題にはなっていません。
タイムラグに関しては、Pub/Sub のoldest_unacked_message_age や、Cloud Function のexecution_times でモニタリングしています。
「イベントソーシングとの組み合わせ」に関して
スナップショット
特定のエンティティまたはエンティティのコレクションのイベントを再生または処理することにより、データの読み取りモデルまたはプロジェクションで使用する具体化されたビューを生成すると、大量の処理時間とリソース使用量が必要になる可能性があります。 これは特に、長期にわたる値の合計や解析が必要な場合に当てはまります。関連するすべてのイベントの検証が必要な場合があるためです。 この問題を解決するには、スケジュールされた間隔でデータのスナップショットを実装します。たとえば、発生した特定のアクションの合計数や、エンティティの現在の状態などです。
これに関してはBigtable のバックアップ・リストアを、Bigtable Backups のスナップショットとPub/Sub Replay の差分バックアップで実現している部分が近いです。
スナップショットだけだと個数に限度 があったり、Replay だけだと保持期間の限度や再処理時間が長くなりすぎたため、これらを組み合わせています。
その他所感
Pub/Sub dead letter を使ったエラーハンドリングの安定感
これはどちらかというとGCP の特徴ですが、 Pub/Sub ではエラー時に指定した回数リトライが失敗した場合にはevent を指定したDead-letter topic に取っておくことができます。
これにより、エラー時のevent をそのまま保持できるため、エラーを取り除いたあとに落ち着いて再処理することが容易になっており、安心感につながっています。
Cloud Function をAPI gateway 的に置いたが、実はCloud Run + Model Serving API のほうがよいかもしれない
当初は、ML ベースへの移行の際にCloud Run の部分をVertex Prediction などのModel Serving API に置き換えることを想定していましたが、 「懸念事項の分離」の観点から、Cloud Run で動かすビジネスロジックと、純粋な推論タスクのModel Serving API は分けたほうがよいと考えるようになりました。
そうなると、Cloud Function を含めると3段構成になってしまいやや冗長なので、直接Pub/Sub からCloud Run に受けたほうがよさそうです。
ただ、ここでもCloud Run でのpush のスケーラビリティには気を使わなければいけないので、同期要件と想定負荷とのバランスを見つつ、Dataflow によるpull 処理も考慮にいれた検討が必要です。
まとめ
全体的に見ると、基本的には今回のアーキテクチャに関しては今のところポジティブですが、細かいところはまだ改善の余地があります。
まだML ベースへの移行が完了しておらず、まだ明らかになっていない要件がこれから出てくる可能性がありますが、
同様のシステムを検討している方の参考となれば幸いです。
*1:『学びを、もっと、新しく。』 〜 AI で進化するスタディサプリの学習体験 〜 の「学習レコメンデーション機能」 を参照