こんにちは、データグループのマネージャーをやっています beniyama と申します。
先の記事『プロダクトの「負債」を「機能」と呼び直す 〜A/Bテストを用いた"価値"の定量化〜』でも触れられていますが、データグループではデータ分析基盤の構築(参考資料)からデータ分析、あるいは学習データを活用した研究開発までスタディサプリのデータに関わることほとんど全てを担当しています。
プロダクトや事業 KPI の社内向けモニタリング環境の構築・整備も行なっているのですが、今回、既存の環境を刷新して Looker というまだ日本ではほとんど無名?のツールを導入することにしましたのでその経緯をお話ししつつ、今後国内でもユーザーが増えていくといいなという願いを込めて1エンジニアとして興奮したポイントを書き連ねていこうと思います。
最初の1年間は DOMO を導入して運用
スタディサプリではもともと各種 KPI の可視化に DOMO という BI ツールを導入していました。こちらが実際のダッシュボードで、主に事業側の人たちがサービスのコンディションを把握するために使っています。

DOMO の長所は何と言ってもエンジニアでなくとも綺麗な UI でさくさくカードを作ったり ETL(Extract, Transform and Load)の処理を記述していけるところです。さらに DWH(Data Warehouse)として強力なインフラを提供しているので、様々なデータソースからとりあえず生のデータを突っ込んでおいて DOMO 上で結合・変換・加工などの処理をかけてそのまま可視化することが可能です。
目玉機能を使い切れず費用対効果に悩む
さて、サクサクカードを使っていざ活用!というステップに差し掛かると、次に考えないといけないのはいかに多くのユーザー(= サービスに関わる全ての人)に見てもらうかです。もちろん画像にしてメールで一斉配信…などもできるのですが、せっかくのダッシュボードツールなのであればいつでも最新の状況を見たいですし、その場で軽めの分析をするためにインタラクティブにフィルターをかけたりドリルダウンしたりしたいのが人情というものです。
しかしながら、サービスもそれなりの規模になってきたこともあって関係者それぞれにアカウントを発行して運用するのが(主にコスト面で)難しく、なかなかデータの民主化を推進することができませんでした。DOMO 自体は非常に素晴らしいツールなのですが、売りにしている機能を使わなかった(使う必要がなかった)こともあって「ちょっと見てみたいんですけど…」と相談された時に『費用対効果』の5文字が頭を巡るシーンが増えてきました。
ちなみに使わなかった点は大きく二つあって、
1. DWH をすでに作ってしまっていた
既に内製のデータ分析基盤を持っていたのでその中でデータマートを作ってあとは可視化だけしたい!感じだったのですが、前述の通り DOMO は ETL までカバーできるスペックも売りにしていたので宝の持ち腐れ感がありました。既存の運用や外部システム連携もあって全て DOMO に移管するというのも難しい状態でした。
2. 社内コミュニケーションは Slack で完結していた
DOMO には Buzz という DOMO の中で各カードごとにコメントをつけたりしてコラボレーションできる機能があるのですが、既に社内のコミュニケーションは Slack で完結していたのでなかなか新たに Buzz で会話をしたりするようにはならず、こちらも宝の持ち腐れとなってしまっていました。
そこでもう少し軽量なツールを探している最中に出会ったのが Looker でした。
エンジニアの LOVE が詰まった BI、それが Looker
本当の営業活動は契約後に始まる、クラウドが変えた米ITベンダーのビジネス戦略によれば、Looker には『Department of Customer Love』という部門があるそうです。確かに Looker の特徴を見ていくとエンジニアの LOVE を感じずにはいられません。
データグループでは現在 Looker のノウハウをためながら着々とモニタリング環境の整備に取り組んでいて、先のダッシュボードも今こんな感じでどんどん置き換えられています。
それではここで Looker の特徴について説明していきましょう!
1. 外部の DWH・DB を使うことを前提にしている
よくある BI ツールと異なり、Looker は BigQuery や Redshift、あるいは一般的な RDB と組み合わせて使用することを念頭に設計されています。Looker ではそれらの DWH や DB に対するクエリを自動生成し、結果を取得して表示するというシンプルな構成です。もちろん、中間テーブルを介した値の変換や前処理も記述可能ですが、それも Looker 内にデータを保持するのではなく変換用のクエリが発行され、中間テーブルも DWH・DB 内に作成されることになります。
私たちのケースでは前述の通り DWH を持っていましたので、それに対するクエリを生成して可視化してくれるという役割はぴったりハマりました。具体的には Treasure Data で集計したデータマートを BigQuery に連携し、そこに対して Looker からクエリを発行する構成になっています1。また、次に説明する通りこのクエリが構造的に定義できるというのがさらに強力なポイントです。
2. LookML で全てを記述できる
よくある BI ツールと異なり、Looker はデータソースの指定から measure や dimension といった項目の定義まで LookML という YAML ベースの書式で記述することが可能です。可読性や検索性が向上するだけでなく指標の定義が一元管理されるので、ユーザーがそれぞれオレオレ計算やオレオレ指標を作ってカオスになることを避けられます。
例えば What is LookML? にある例を見てみると E-commerce ストアをモデルとして下記のように定義しています。
###################################### # FILE: ecommercestore.model.lkml # # Define the explores and join logic # ###################################### connection: order_database include: "*.view.lkml" explore: orders { join: customers { sql_on: ${orders.customer_id} = ${customers.id} ;; } }
モデルでは DWH や DB とのコネクション設定を指定して、そこからどのテーブルを持ってくるかを定義します。例えばここでは order_database コネクションを使って orders というテーブルを SELECT しつつ、customers というテーブルと orders.customer_id = customers.id という条件で LEFT JOIN しながら引っ張ってくることを定義しています。
次にビューを見てみると、
########################################################## # FILE: orders.view.lkml # # Define the dimensions and measures for the ORDERS view # ########################################################## view: orders { dimension: id { primary_key: yes type: number sql: ${TABLE}.id ;; } dimension: customer_id { sql: ${TABLE}.customer_id ;; } dimension: amount { type: number value_format: "0.00" sql: ${TABLE}.amount ;; } dimension_group: created { type: time timeframes: [time, date, week, month] sql: ${TABLE}.created_at ;; } measure: count { type: count drill_fields: [drill_set] } measure: total_amount { type: sum sql: ${amount} ;; } set: drill_set { fields: [id, created_time, customers.name, amount] } }
となっており、先ほどの orders テーブルからどういった measure と dimension を定義してユーザーに提供するかが定義されています。
例えば
dimension: id { primary_key: yes type: number sql: ${TABLE}.id ;; }
は orders.id がプライマリキーであり、数値型。そして ${TABLE}.id つまり orders.id をそのまま使用する、という意味になります。かつこれは、足し上げたり平均をとったりする類のものではないので dimension が指定されています。
一方、
measure: total_amount { type: sum sql: ${amount} ;; }
では measure が指定されていて、これはここに指定されている SUM のような集計関数にかけることが可能です(dimension で GROUP BY をかけるイメージ)。ここでは amount という値の和を計算して total_amount として参照できるように定義していますが、この amount というのは
dimension: amount { type: number value_format: "0.00" sql: ${TABLE}.amount ;; }
こちらで定義されており、元々は orders.amount からとってきていますがその時小数第二位まで保持するように指定されています。このように、measure や dimension の定義がまた別の定義の中から参照できるので、ビジネスロジックの共通化や再利用が可能となります。この他、フィルターを指定(WHERE 句のイメージ)したり、ドリルダウン時にどのような項目でまとめ上げるのかといったことも記述することができます。
YAML ベースで編集したりデバッグできるということは、当然バージョン管理もしたいですよね!
3. BI ツールなのに GitHub 連携ができる
よくある BI ツールと異なり、Looker はモデルやビューの定義の変更を自動的に GitHub をはじめとした Git リポジトリに同期してくれます。つまり意図せぬ変更をしてしまったとしてもすぐ履歴を追って復元することが可能ですし、何なら Developer Mode と呼ばれる状態であればブランチが切られるのでそこで人知れずガリガリ変更を行なって良さげなところでプルリクエストを送ってレビューを経てマージ!なんてこともできるのです。
例えば、共同開発していて置いてかれたら Pull しますか?と聞かれますし、新しくブランチ切って進めることも可能です。
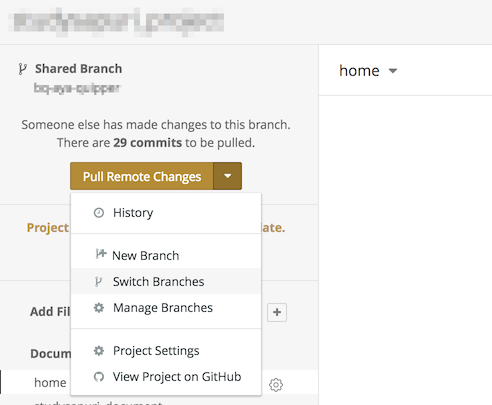
これならたまたまグラフをいじっているときに遭遇したユーザーから問い合わせを受けて弁明するようなこともなく、安心して複数人で開発ができますね!
4. ほとんどの操作を API 経由で実行できる
よくある BI ツールと異なり、Looker は Looker API Reference にある通りダッシュボードの更新はもとよりユーザの管理に到るまでかなりのことが API を通して実行可能です。例えば、以前 DWH 側のデータ更新と BI ツール側のデータ更新のタイミングを合わせることができなかったため、たまたま DWH 側の集計が遅れたときに(更新前のデータを BI 側が吸い上げてしまったので)「BI が更新されてないんですけど!」と問い合わせを受けることがあって困っていたのですが、それも DWH 側の集計が終わったときに Looker の API を叩いてあげるようにワークフローを組めば解決することができます。
また、Lookerbot を走らせることで、Slack 内から /looker のようなコマンドで任意のグラフやデータを取得して共有することも可能です。
5. 見られている・見られていない指標がすぐわかる
よくある BI ツールと異なり、Looker は Look (グラフなどのダッシュボードを構成する要素)やダッシュボードがいつ誰に見られたかを詳細に確認できる下のような画面を提供しています。
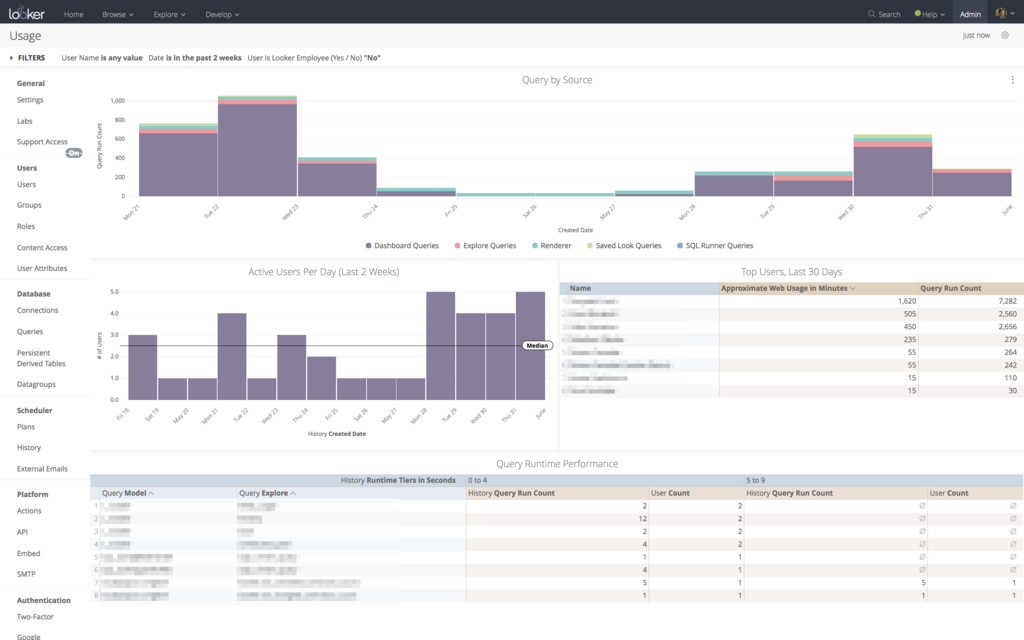
これをチェックすることで、作ってはみたけど全然見られていないグラフや、アカウントはあるけれどアクティブではないユーザーを特定することが可能です。必要があればグラフの定義や見せ方を変えて改善したり、あるいはユーザーにヒアリングを行なってなぜ使ってもらえないかという原因の把握に努めます。もし不要なグラフだったことがわかればそのデータを生成する処理も一緒に除却できますし、あるいは使っていないユーザーのアカウントを停止して他の人に枠を譲ることも可能です。
レポーティング・モニタリングには開発だけでなく運用コストもかかるので常に改善や廃止を続けながらできる限りスリムにしていくことが重要ですが、いずれにせよユーザーの行動に関するメトリクスがなければこのような判断もすることができません。
6. カスタマー LOVE の溢れるサポートがついてくる
よくある BI ツールと異なり、Looker は 先述の Department of Customer Love という部門を持っていることもあってか「導入さえしてもらえばそこで終わり!」ではなく、その後どうすればカスタマーサクセスに辿り着けるかとても真摯に考えてくれています。いつでもチャットでカスタマーサポートに問い合わせをすることができ、その返信も非常に早いです!
日本でももっと広まって一緒に語れる仲間が欲しい
ここまで色々と Looker の興奮ポイントをご紹介してきましたが、当然まだ荒削りというか改善の余地があると感じるところもあります。特にまだ日本で大々的に展開していないので日本語サポートは一つ大きなポイントとなりそうです。
また、グラフの作成画面などはまだ小慣れてきていない感じもあって Tableau や DOMO の方が好みの人も多いかなと思います。集計関数の定義も、ある程度は自動で生成してくれると毎回 SUM や AVG を定義しなくて良いかな…と思うシーンもあります。( v5.14 以降はエンドユーザーが GUI から簡単に custom measure を定義できるようになったそうです! 月に1回新機能をリリースするタイミングがあるそうなので、凄いスピードで改善されていく予感がします)
とはいえ LookML も一度慣れてしまえば特にプログラミングの知識などなくても編集したりグラフを作成することができますし、実際に私たちのチームではエンジニアではないメンバーが主に作業しています。エンジニアが関われば API を活用した外部システム連携も自在ですので、一気にデータ活用の幅を広げることが可能です。ぜひ導入事例が増えて国内外で一緒に色々議論できるようになると楽しいな、と思います!
一緒に働いてもらえる仲間も欲しい
データグループではこれから、日本のみならずインドネシア、フィリピン、メキシコとグローバルに展開している Quipper School のデータ基盤とモニタリング環境をこの Looker を使って開発していこうと思っています。グローバル x データ x 教育 の取り組みにご興味のある方は、ぜひこちらからご応募ください!
- 将来的には BigQuery 単体で完結するようにしていく予定です。↩