
スタディサプリのコミュニケーション開発チームの @chata です。開発実装を行った際に負荷試験をして実際のパフォーマンスがどの程度なのか計測したときの模様を共有いたします。
TL;DR
背景と結果
負荷試験をいざやってみると色々問題が見つかりました。パフォーマンスにおける課題だけではなくアーキテクチャの課題も把握できました。また弊チーム以外でも同じようにやってみたいという声があり活用してもらっています。
負荷試験に関するまなび
負荷試験は3種類のテストをそれぞれの目的で実施すると必要なリソース(CPUやMEM)や台数などの把握が事前にできます。またパフォーマンスの課題も見つけやすいです。
実行環境に関する Tips
SREチームの多大なる支援を背景にPR環境で Report がDeployされる Loadtest Platform を活用することで試行錯誤のサイクルを速くまわすことができた。
1. なぜ負荷試験を実施するのか
弊チームでは、主にスタディサプリのSchool領域、学校及び団体などの組織でのサービス(B2B2C)の利用に関連する機能開発を行っています。主に団体(学校)でのサービスの利用ケースの場合に先生や生徒間、先生と保護者間でのコミュニケーション機能を提供することにより学習支援、主体性、進路実現を促進しています。このコミュニケーション機能では、「お知らせ」、「メッセージ」 などの機能を含んでいます。
<画像> B2B2C領域におけるコミュニケーション開発
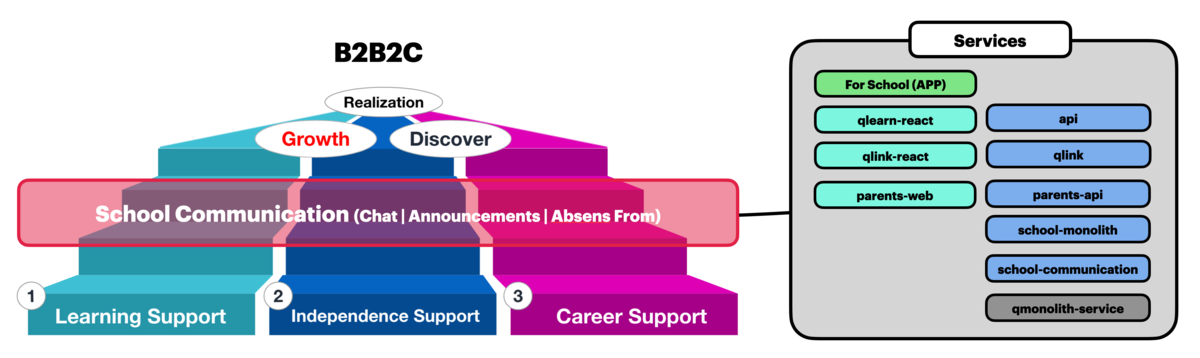
コミュニケーション機能を提供することにより学習支援、主体性、進路実現を促進しています。
コミュニケーション機能は特にパフォーマンスに対しての影響が大きくなることが想定されています。さらに「お知らせ」や「メッセージ」の機能は一括で送信したりする場合に高負荷がかかると予想されます。(実際にコロナ禍において、休校などが実施された際にコミュニケーションの機能には大きな負荷がかかりました。)
そういった高負荷のかかる処理や高頻度のリクエストに対して、期待する機能が提供できるのか、関連するサービスに悪影響を及ぼさないかを事前に把握した上でのリリースへと繋げていくことが重要という位置づけになりました。ただし明らかに高負荷とはならないことがわかっている機能についてはリリースしてから負荷の状況を見るという形も選択肢になっています。(高負荷が予想されるサービスの重要なシナリオなどについては実施というスタンスです。)
そして、もう一点ですが弊チームの実装される新機能については Microservices(マイクロサービス) であるということです。弊チームが提供する新たなサービスの信頼性は他の既存サービスの信頼性に依存するため、他の既存サービスに対してどの程度の影響を与えていくのかという部分と、その弊チームが提供する新たなサービスと他の既存サービスが適切にスケールアウトしていくのかという部分をリリースの前段で把握することが重要という位置づけになっています。
このマイクロサービスのアーキテクチャの特徴や依存についてはこちらの記事が参考になります。
これらの理由から、負荷試験をリリース前に行い課題や問題点、そしてシュミレートされる負荷の状況を把握することでリリースされた際の不安を解消していくことに寄与しています。
2. 負荷実行ツールの選択
負荷試験を実施するにあたり、実施に際して手段をどうするかという問題があります。 取れる選択肢は色々ありましたが主に以下の方法です。
- 弊社Globalで利用実績のある
Locust - 気軽に実施できる
Apache Benchmark/Curl - 伝統と実績のある
JMeter - Scalaでシナリオ作成の
Gatling
何が良い悪いということも使用ケースによるので無いのですが、弊チームではレポートのみやすさやカスタマイズ性で Gatling を選択しています。Scalaを勉強しないといけなかったのでちょっと心配でしたが、ツール自体が人気がありドキュメントやレファレンスもそろっていたたため思ったよりも苦もなくシナリオを書けました。
レポートは非常に見やすい形になっています。95%TileでのレイテンシやKO(Error)の発生タイミングや原因などもRequestごとにまとまっておりテストの実施状況が把握がしやすいレポートだなと感じます。さらにこのレポートと合わせて Datadog でのリソースの使用状況などを確認することによって負荷試験実行時の様々なボトルネックを発見することが可能になっています。
<画像> レポートのSTATUSTICS
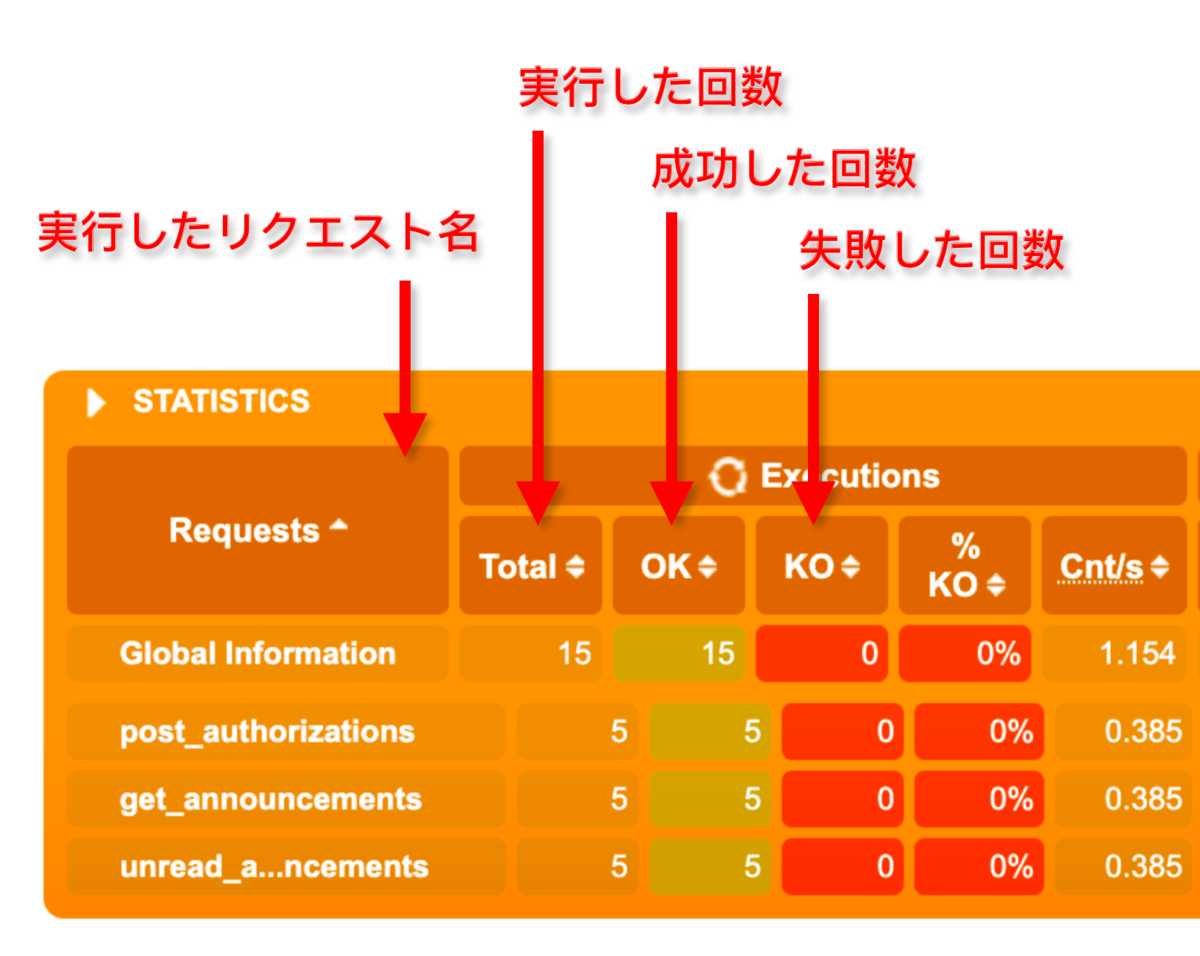
上記の画像の様に
STATUSTICSで実行したリクエストのサマリが確認できます。OKが成功、KOが失敗の回数です。
3. テストモードの種類
弊チームでは、負荷試験を行う際に以下のテストモードを最低限実施する形にしています。
- パフォーマンステスト
- ロードテスト
- ストレステスト
負荷試験を実施する上で、 Requimement(要件) / Acceptance Criteria(合否基準) を定めてPMやQAの担当者などのステークホルダーと合意をとった上で実施することにしています。要件および合否基準は、過去のアクセス履歴などから規模を想定し指標を定め、その指標を満たすことを目的とした負荷試験を行います。この要件および合否基準を満たさない場合は協議の上でボトルネックを調査し改善を行うなどの措置を行います。
それぞれのテストモードの目的を以下に記します。
パフォーマンステスト
- オートスケールを無効にした状態で指標要求到達確認/リソースの調整
- リソースの調整(CPU/MEM)
- maxCapacityの設定
- 指標に対してエラーが発生しない状況になるのが望ましい
ストレステスト
- オートスケールを無効/有効にした状態でキャパシティおよび限界値の確認
- リソースの調整(CPU/MEM)
- minCapacityの設定
- エラー発生状況の確認
ロードテスト
- オートスケールを有効にした状態でオートスケールの有効性の確認
- オートスケール時のMetricsのしきい値などの調整
4. テスト実施環境
負荷試験を実施するにあたりもう一つの課題が見えてきました。負荷試験を実施する環境をどうするかという問題です。これは、通常の開発を行っている環境やDBなどに対して負荷試験を実施してしまうと大量の不要データが作成されたり、思わぬ所でリソースが不足しOOMなどが発生してしまう可能性があります。
また負荷試験を行う上でも他チームのアクセスや実装にともなうリソースなどの利用によって負荷試験のレポートにノイズが入ってしまう状況が予想されました。そこで、SREチームと相談して独立した環境で負荷試験を行うことにしました。これによって負荷試験時のノイズの心配もなくなり、安心安全な負荷試験を実施できることとなりました。(Yay!)さらに、Github Actionsを通して、Gatling実行時に生成されるレポートもDeployされてActionの実行単位でレポートがWEB上で確認できます。Zipファイルをローカルにダウンロードして解凍する必要もありません。便利。
この負荷試験実施環境については改めてブログの記事になるかと思います。(お楽しみに!)
5. テストデータの話
もう一点、特筆すべき点といえばテストデータについてです。弊チームで負荷試験を実施するにあたりテストデータとテストデータセットをどの様にマニュピレートするべきかという点でした。
今までの簡単な負荷試験のときはテストを実施する際にCSVなどのデータセットを用意して、各行に対してテストを実施するような形やSQLやクエリを実行してデータを整形するなどという手段をとっていましたが Gatlingでは feeder を使ってシナリオ上でダイナミックなテストデータセットを作成することが簡単にできます。そのため予め必要なテストデータもシナリオ実行時に各DBクライアントが必要なDBへ直接接続してデータを作成したりリセットしたりすることができるようになっています。
Feederを使用したサンプルコード
import io.gatling.core.Predef._ import io.gatling.http.Predef._ import org.mongodb.scala._ ... // DB接続設定 val mongoClient = MongoClient(sys.env("MONGODB_URI")) val usersColl = mongoDb.getCollection("users") // DBにクエリを投げてデータを取得 val userMap = usersColl .find(in("_id", userIds: _*)) .projection(include("username")) .results() .map(r => r.getOrElse("_id", null).asObjectId -> r.getOrElse("username", null).asString.getValue) .toMap // feederにわたす配列を作成 val requests = (for ((username, password) <- userMap) yield { Map( "accessTokenParams" -> s""" |{ | "email_or_username": "${username}", | "password": "${password}", |} |""".stripMargin, ) }).toArray.circular // feederのStrategiesを定義 (ここではcircularを使っています。) // Gatlingでシナリオを実行するためのhttpProtocolを定義 val httpProtocol = http .baseUrl(sys.env("URL")) .userAgentHeader("Gatling") // Gatlingでシナリオを定義 val scn = scenario("Login") .feed(requests) // <= ここでfeedにrequestsを渡す .exec( http("auth") .post("/auth") .disableFollowRedirect .body(StringBody("${accessTokenParams}")) .check(bodyString.saveAs("response1")) .check(jsonPath("$..token").saveAs("token")) .check(status.is(200)) ).exec { session => if (printResponse) { println(s"""[Result 1] ${session("response1").as[String]}""") } session } ... // 実行 setUp(scn...)
これにより多少のテストデータの作成などは必要ですがそれ以降ではテストのシナリオごとにテストデータを調整したり、データセットを自動で作成できるようになっているため便利になったと感じます。
6. やってみた結果
実際に負荷試験をしてみるとさまざまな課題や問題点が見つかります。パフォーマンス要求を満たすためにボトルネックとなっているリクエストやリソースの設定、実際に期待通りにスケールアウトが進まないことなどの問題点が負荷試験実行時に検知されました。しかし、リリース前の段階でこのような課題が見つかることによって事前に解決に向けた対策を打つことができます。または、要求を満たすために 金の弾丸 でリソースに余裕ももたせたホットスタンバイを用意させておくことが可能です.
運用時の対策としては、ユーザー登録時などを一斉に行う可能性のあるユーザー登録会で登録ボタンを一斉に押すようなオペレーションは高負荷を与える原因となるため、そのようなオペレーションをしないようにという案内を各方面に展開し実施していただいています。
そしてリリース以降は、定期的に SLO を監視しつつ負荷の問題など発生していないか、リソースは足りているかなどをモニタリングすることでサービス品質を保っています。
SREチームの協力も得て、Kubernetes 上の Github Actions Self-hosted Runner で負荷試験をワンストップで実行できる仕組みにより、ボトルネックの発見と解決を速いサイクルで進めることができました。その改善に合わせて他チームでもGatlingを使用した負荷試験の活用につながっています。今後は、QAチームなどとも連携を強化しつつ性能評価などの品質管理へと接続していきたいと思っていっます。
皆様も快適な負荷試験を!以上です。