こんにちは。SRE の @chaspy です。
Quipper では Application Platform として Amazon EKS(以降、EKS)を利用しています。*1これまで Cluster を Upgrade する際には Blue/Green 方式で行っていましたが、今回 Canary 方式で Cluster の切り替えを行いました。*2
本記事では、AWS EKS を Canary Switching*3する方法を説明するとともに、それによる様々な利点を紹介します。AWS EKS を使っているひとはもちろん、Platform の Canary Switching を検討しているひとにも役立つと幸いです。
なぜやるのか
前回の記事で紹介した通り、Cluster Switch には以下の2つの問題がありました。
1つ1つ見ていきましょう。
Canary Switch することの利点
これを考えるために、信頼性の考え方を振り返ってみましょう。
信頼性を表現するためには、以下の3つの指標が重要です。
- MTTD: Mean Time to Detect
- MTTR: Mean Time to Resolve
- Impact Users
上記の指標を利用して、障害の影響は以下の式で表されます。*4
Impact Users * (MTTD + MTTR)
Canary Switch が何を助けるかというと、この Impact Users を減らすことにあります。いきなり全ユーザに公開してしまった場合、仮にすぐロールバックして MTTD + MTTR を最小限にしたとしても、被害の量はかなり大きくなってしまうでしょう。
旧クラスタと独立して新クラスタで動作確認をする利点
Staging・Production 問わず、Cluster は常時利用されています。しかし、Blue / Green Dewployment 方式で切り替える場合、新クラスタに実際のトラフィックを一度も流すことなく切り替えることになります。もし切り替え後に問題が発生した場合、ロールバックして調査する必要があります。これには時間がかかりますし、問題発生中はクラスタが使用できないことから、Staging Cluster の場合 Developer の Productivity を著しく下げてしまいます。これは実際に前回の EKS 移行のときに感じた課題です。
Staging であれ、"通常営業"を続けながら、新しい環境で Developer 自身に動作確認をしてもらえることは双方にとって利益が大きいでしょう。
どうやるのか
Cluster 付けの Ingress を廃止し、Cluster に依存しない ALB を配置しました。以下のような図の構成になります。
Before
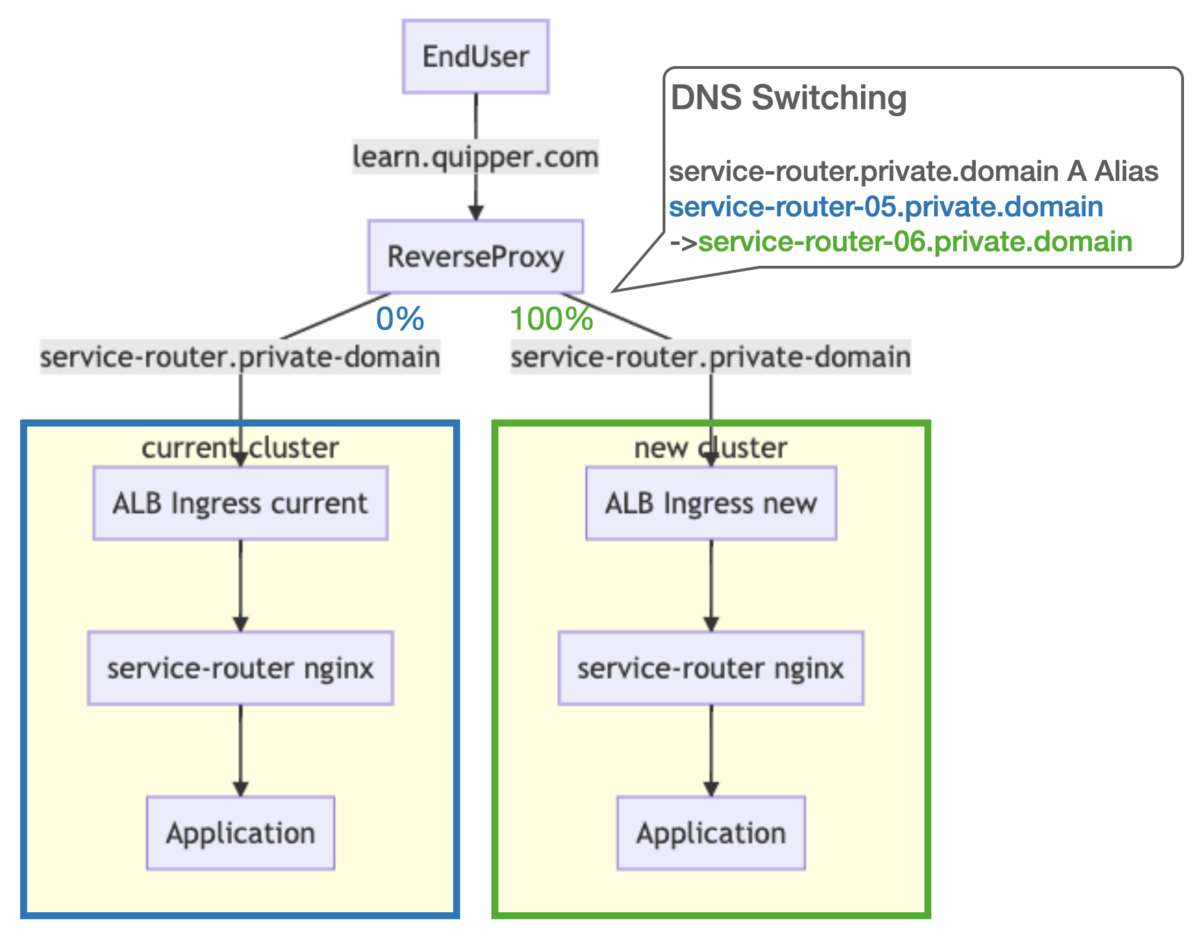
以前は DNS で loadbalancer の record を対象にしている Record を切り替えることで、100% 一気に切り替えていました。
After: Canary Switching
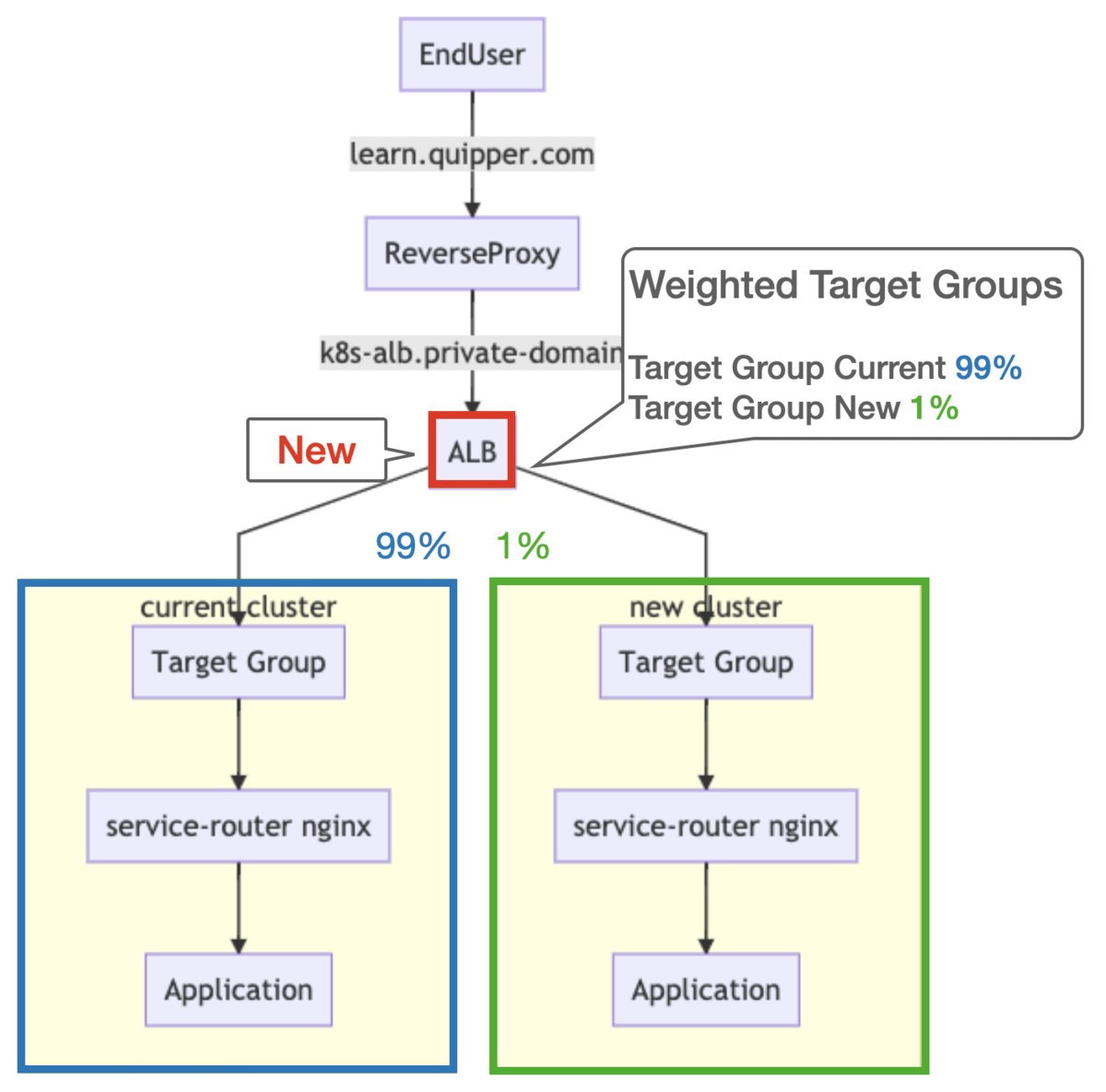
このように ALB Weighted Target Groups の機能を使い、Percentage-Based で切り替えることができるようになります。
具体的には、Managed Node Groups を作成時に生成される AutoScalingGroup を Target Group に紐付け、ALB からは Listener Rule でその Target Group に転送します。
切り替え前は 100% 現クラスタに向けておき、徐々に新クラスタへと Percentage をあげて切り変えていきます。
After: Testing a new cluster by host-based routing
また、Host-Based Routing の機能により、特定のホスト名に合致した場合は新クラスタへルーティングすることも可能になりました。
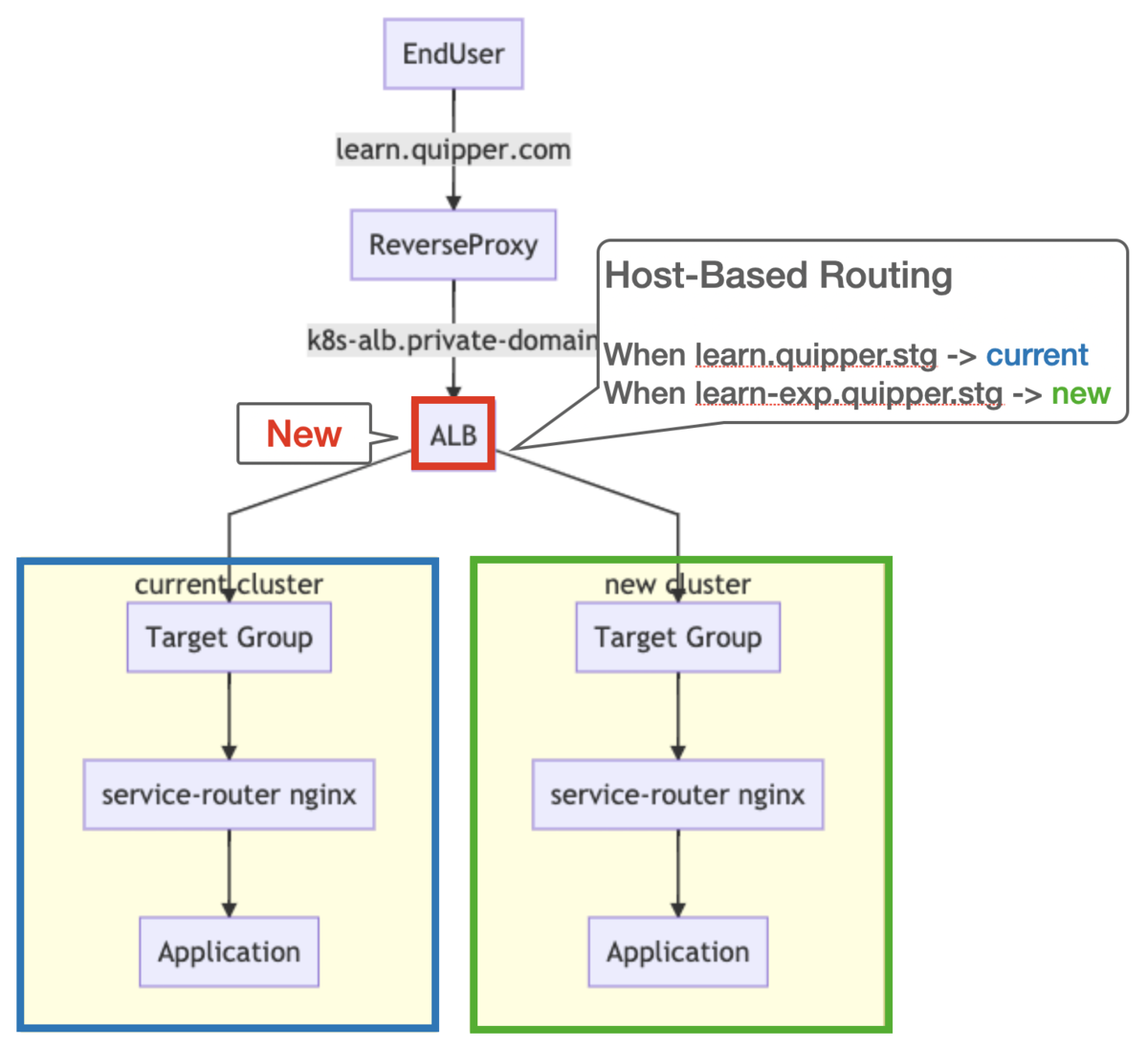
どう切り替えるのか
aws cli をラップする簡単な shell script*6 を書き、 Monitoring をしながら手動で切り替えました。
#!/bin/bash
set -eu
# Validate arguments
if [ $# -ne 4 ]; then
echo "Invalid auguments: $*"
echo "Usage: ./modify_weighted_target_group.sh product environment weight1(current) weight2(new)"
echo "Example: ./modify_weighted_target_group.sh quipper staging 10 90"
echo "NOTE: Please run show_weighted_target_group.sh before running this script."
exit 1
fi
PRODUCT=${1}
ENVIRONMENT=${2}
WEIGHT1=${3}
WEIGHT2=${4}
LOAD_BALANCER_ARN=$(aws elbv2 describe-load-balancers --names k8s-"${PRODUCT}"-${ENVIRONMENT} | jq -r '.LoadBalancers[].LoadBalancerArn')
LISTENER_ARN=$(aws elbv2 describe-listeners --load-balancer-arn ${LOAD_BALANCER_ARN} | jq -r '.Listeners[].ListenerArn')
TARGET_GROUP_ARN_1=$(aws elbv2 describe-target-groups --load-balancer-arn ${LOAD_BALANCER_ARN} | jq -r '.TargetGroups[0].TargetGroupArn')
TARGET_GROUP_ARN_2=$(aws elbv2 describe-target-groups --load-balancer-arn ${LOAD_BALANCER_ARN} | jq -r '.TargetGroups[1].TargetGroupArn')
# Sort target group arn
# Since the order of target groups returned by describe-target-groups is non-deterministic
SORTED_TAGET_GROUP_ARN=$(cat << EOF | sort
"${TARGET_GROUP_ARN_1}"
"${TARGET_GROUP_ARN_2}"
EOF)
TARGET_GROUP_ARN=$(echo -e "${SORTED_TAGET_GROUP_ARN}" | head -n1 )
NEW_TARGET_GROUP_ARN=$(echo -e "${SORTED_TAGET_GROUP_ARN}" | tail -n1 )
aws elbv2 modify-listener \
--listener-arn "${LISTENER_ARN}" \
--default-actions \
"[{
\"Type\": \"forward\",
\"Order\": 1,
\"ForwardConfig\": {
\"TargetGroups\": [
{ \"TargetGroupArn\": "${TARGET_GROUP_ARN}", \"Weight\": "${WEIGHT1}" },
{ \"TargetGroupArn\": "${NEW_TARGET_GROUP_ARN}", \"Weight\": "${WEIGHT2}" }
]
}
}]"
以下を実行することで 1% だけ新クラスタにトラフィックを流します。Dashboard を確認し、エラーレートがあがってないことを確認して、徐々に Percentage をあげることを繰り返します。
bash modify_weighted_target_group.sh quipper production 99 1
実際には以下のような流れで行いました。
- 新クラスタですべての Kubernetes Resources が Running であることを確認する
- 1% のトラフィックを新クラスタに流す
- Datadog Dashboard でエラーレートを確認する
- 2 と 3 を繰り返して徐々にトラフィックを増やしていく。今回は 10%, 20%, 50%, 100% の刻みで増やしました。
トラフィックの増加は10分ごとに行ったので、合計1時間弱かかりました。
学んだこと: 日中にクラスタ切り替えを行うことができる
ALB Weighted Target Groups には Weight を 0-999 が指定できることから、通常のトラフィックの 0.1% ずつから新クラスタに流すことができます。これにより影響範囲を小さく抑えることができ、安心して切り替えることができました。
これまで Blue / Green Deployment 形式で切り替えをやっていた時は、ユーザ影響をできるだけ避けるため、トラフィックが少ない深夜に行っていました。今回、この Canary Switching によって、深夜でなく日中でも十分に安全に切り替えられることに気づきました。
これは SRE が深夜稼働する回数を減らすことができます。SRE の健康はサービスの健康です。夜は寝ましょう。
今後の課題
Metrics による 自動 Rollout / Rollback までは現状考えていません。もしそれができれば素敵ですが、それを判断する SLI/SLO が定かではないこと*7、そしてクラスタ切り替えの頻度がせいぜい3ヶ月に1回とさほど多くないためです。
とはいえいざ切り替えをやってみると、パーセンテージを変えて、しばらく待つ、というプロセスは1時間かかり、面倒に感じました。自動 Rollback/Rollout が判断できる Metrics / Alert が定まったら挑戦してみたいと考えています。
おわりに
今回、EKS Cluster の Upgrade をさらに安全に行うことができるようになりました。Productivity と Reliability を両立する "Progressive Delivery"*8 を Infrastructure Layer で実現することで、Application に対してもノウハウを展開し、それが"当たり前"な世界に変えていきます。
Quipper では世界の果てまで学びを届けたい仲間を募集しています。
*1:EKS 切り替えの話はSelf-Hosted Cluster から EKS への移行と Platform の Production Readinessをご覧ください。
*2:Kubernetes を v1.15 から v1.17 へ Upgrade しました
*3:Canary Release方式で、クラスタを切り替えました
*4:定義はGOOGLE CLOUD PLATFORM Know thy enemy: how to prioritize and communicate risks—CRE life lessons を参考にしています
*5:Service Router はクラスタの入り口にいる、各 Kubernetes Service へ Routing する Nginx のことです。https://quipper.hatenablog.com/entry/2020/08/11/migration-to-eks#f-8ab45b30
*6:TARGET_GROUP_ARN を sort している理由は cli が返す json の TARGET_GROUP の順番が非決定的だからです。Quipper では Cluster に数字をつけているので、sort することにより必ず引数の前半で指定したものが現在のクラスタ、後半で指定したものが新しいクラスタの Weight を変更するようになります。
*7:Platform SLO は定めましたが、それはあくまで Deploy の品質を評価するものであるため
*8:コントローラブルにデプロイする考え方。Canary Release はその 1 手法