こんにちは。SRE の @chaspy です。
Quipper の SRE Team ではじめて「オンボーディング」と呼ばれるものを行って約2年経ちました。
その後、3人の仲間が入社し、そのたびにオンボーディングプロセスを改善してきました。
本記事では、SRE Team のオンボーディングプロセスの"いま"を振り返るとともに、その効果や意義を、オンボーディングを受けたメンバーからのコメントを交えて紹介したいと思います。
オンボーディングの目的
あらためてオンボーディングの目的について言語化しておきます。これは今も昔も変わっておらず、「New Joiner の早期の戦力化」だと思っています。
早期の戦力化のためには何が必要か、ということを考えると、現在のチームのミッションから普段の業務へブレークダウンし、それらをスムーズに遂行するために何が必要かを考える必要があります。
私たち SRE Team のミッションは"本番環境の安定運用"であることは言うまでもありません。しかし、いわゆる"オンコール"のような Reactive な仕事以外も、障害を未然に防ぐような Proactive な仕事もあります。また、組織とシステムをスケールするために開発者をサポートする仕事もあります。
このように多岐にわたる SRE Team の業務の重要な観点をざっくりブレークダウンするとこんな感じになります。*1
こういった仕事のカテゴリがある中で、*5もっとも重要なのは「既存システムの理解」だと考えます。また、Developer Productivity の向上や、Platform 開発のためには「Developer との関係構築」も重要でしょう。
この2年間はこれら2点を重視してオンボーディングプロセスを改善してきました。
オンボーディングプログラムのいま
現在のオンボーディングプログラムは以下のようになっています。
- アカウント登録
- Learning Session
- Happy Path Test の体験を通したプロダクトの理解
- Good first issues のペア作業によるシステム構成の理解
- Postmortem 読書会
- ペア・アラートハンドリング
また、受け入れ側としては以下2点を行い、問題の早期解決に努めました。
- 1on1
- 他チームとの関係構築支援
アカウント登録
これは以前からやっていたものですが、AWS をはじめとする各種 SaaS アカウントの登録を行います。
大半の SaaS は既存メンバーが Invite しますが、AWS の IAM はコードで管理されているため、New Joiner は入社初日に自分で Pull Request を出して自分自身をメンバーに追加します。
Learning Session
「既存システムの理解」を目的に、各メンバーがそれぞれセッションを担当し、適当な粒度で New Joiner に向けて説明します。重要度が高く、いずれ学ぶ必要になるものは先にインプットしておいたほうが合理的だからです。
最新のセッションでは以下のようなお題目で行われました。
- Kubernetes Cluster
- GitOps
- AutoScaling*6
- SRE Culture*7
- Architecture overview
- Observability
- Unicorn
- MongoDB
- AWS Secrets Manager
- monorepo CI/CD
各テーマはそれぞれ得意なメンバーがセッションオーナーとなり説明を行いました。
こういったものは、当然その一回限りでは完全に中身を理解することは難しいと思います。しかし、ここで"一度"触れておいて、「そういえばあったな」と後から思い出せることは理解を促進させるでしょう。また、セッションの資料はインデックスの役割を示すので、必要になったときに必要な情報にアクセスできるようになるでしょう。
Happy Path Test の体験を通したプロダクトの理解
StudySapuri 小中高・Quipper では Weekly Release の際に Happy Path Test と呼ばれる Regression Test を外部の会社にお願いしています。このテストの一部を行うことで、プロダクトの機能とシステムとの関連性を理解してもらいました。
また、この過程でテスト環境を自分で構築することで、開発環境の作り方とトラフィックフローを理解することもできました。*8
Good first issues のペア作業によるシステム構成の理解
New Joiner 入社前に、事前に Good first issue label をつけておき、その中から適切なサイズのものを選んでやってもらいました。
これによってメインのリポジトリの Release / Deploy の方法や、Pull Request によるレビューといった基本的な仕事をしながら、システムの構成理解を深めていきます。
Postmortem 読書会
過去の Postmortem 合計 30件 をすべて目を通しました。これも「既存システムの理解」を支える施策です。これにより、(Timeline を見たり Slack Thread をみることによって) 障害を追体験できる点も Incident Response の事前準備として非常に有効です。
見ていくと「もうこれは"根本対処"が導入されたので今は起きません」*9といったものも多く、システムの進化を感じられる点がよかったです。
今回 Postmortem をはじめた @chaspy がすべて説明を行いました。これは相対的に在籍年数も長く、Postmortem の内容を説明できるからです。しかし、逆に新しいメンバーが自分が在籍する以前の Postmortem を説明できるようになっていない点は課題を感じます。
この Postmortem 読書会を行うためには、「障害に対して Postmortem がきちんと書かれている」「TODO が消化され、クローズされている」ことが前提です。クローズされていない Postmortem がいくつか残っている点は課題です。
ペア・アラートハンドリング
現在 SRE Team では毎日のアラートハンドリングを当番制にしています。アラートハンドリングは SRE のもっとも重要な仕事の1つである「Incident Response」のために必須ですが、アラートがどういう意味で、何が原因で発生して、どうアクションをすればいいかを知ることは非常に難しく、「既存システムの理解」なしでは行えません。
いきなり防火服を着て現場に向かうのではなく*10、まずは訓練が必要です。
まず、どういったポリシーでアラートが発報されるのか、その Severity と Channel 規約を説明しました。
(参考: SRE Lounge #12での発表)
SRE Team では毎日の Daily Standup で日々きているアラートを確認し、アクションを決めています。こういった日々の活動も New Joiner の理解を支えていると感じます。
1on1
1on1 は基本的には Engineering Manager が各メンバーと一定間隔で行っていますが、それに加えてメンターとの 1on1 を週に一回行っています。
1on1 自体の意味や効果を特にここではとりあげませんが、少なくともオンボーディングに対する重要なフィードバックをもらえる場だと感じています。わかったこと、わかっていないことをフィードバックしてもらうことで、オンボーディングプロセスそのものを改善することができます。
他チームとの関係構築支援
SRE Team は開発者との関係を作ることは非常に重要です。開発者から問題を受け取りやすくすることであったり、システムに問題があった時に一緒に問題を解決していくためには普段から関係を作っておくことが重要です。
在籍年数が長いことの唯一(?)の強みがこの点で、私は New Joiner に比べて、システムとチームの紐付け、キーパーソンが誰かといったことを把握しています。そのため、「さりげなく」関係をつなぐような振る舞いを意識的に行いました。
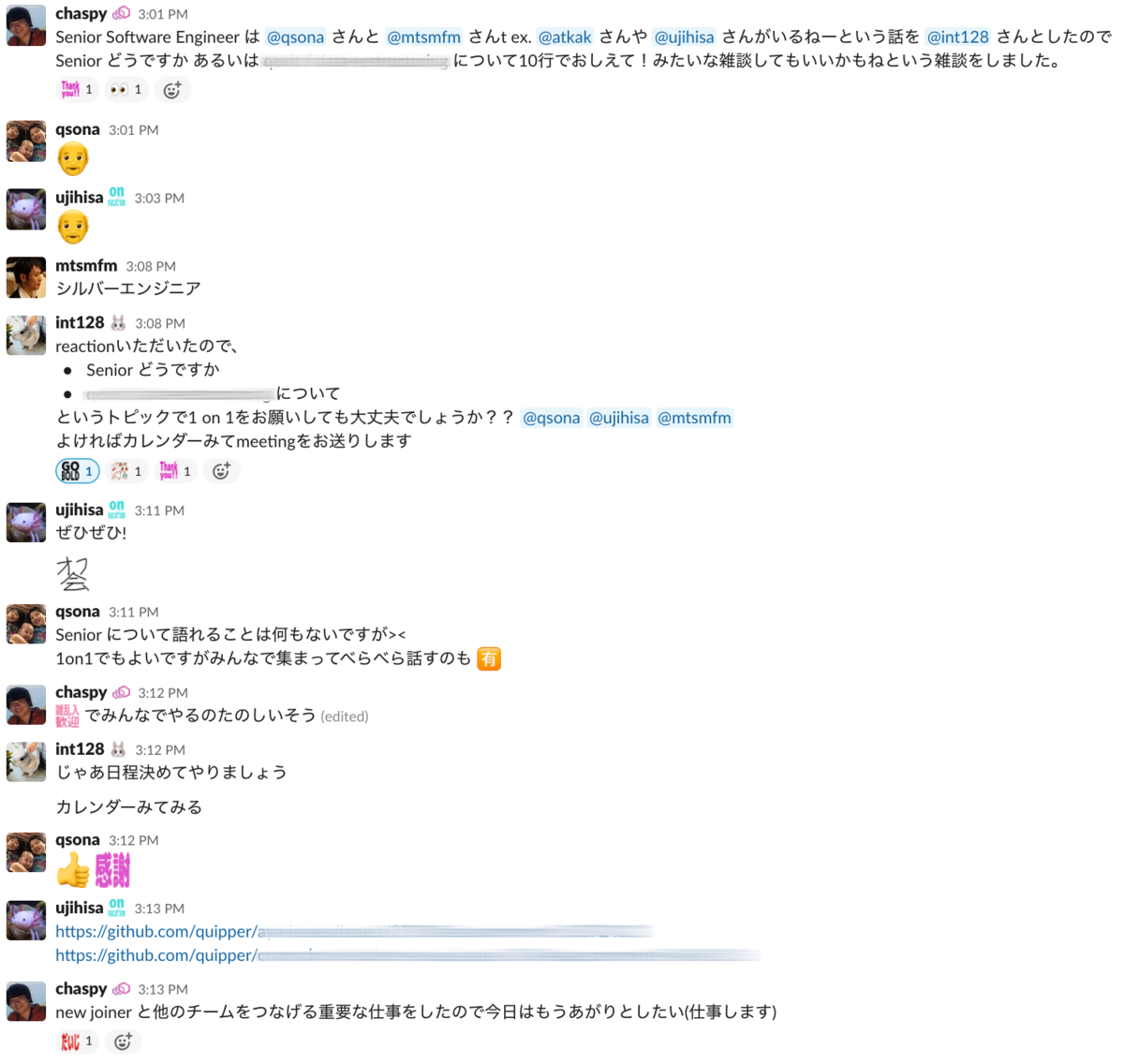
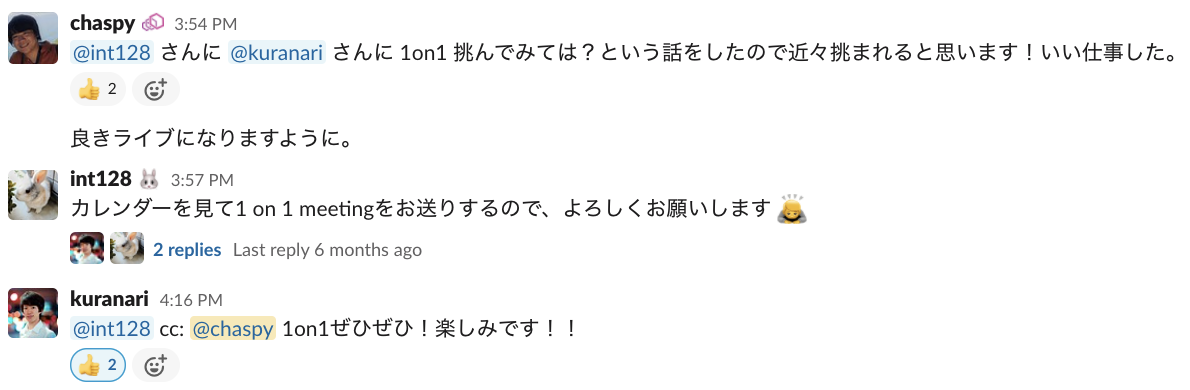
- Senior Software Engineer*11を呼んで雑談
- School Product Team メンバーとの 1on1
オンボーディングのこれから
最後に、オンボーディングさらに改善していくために考えられる課題について述べます。
Incident Response の模擬実験: Chaos Engineering
よく障害対応は Fire Fighting ... 火消し作業に喩えられますが、防火服の着方もわからない状態でいきなり現場にいっても何もできませんよね。
障害対応に関しても適切な学習体験を設計する必要があります。Postmortem 読書会はそれらを追体験できる良い施策ですが、欲を言うともっと臨場感のある訓練をしたいものです。
先日の SRECon Americas 2020 でも Chaos Engineering のセッションは多数とりあげられており、「既存システムの理解」に対してうってつけの策だと聞きながら思いました。
少しずつですが、オンボーディングのさらなる支援と、重要なアラートがちゃんと発報するかの定期点検をかねて、Chaos Engineering に挑戦していきたいと考えています。
Postmortem の活用改善
Postmortem の数はどんどん増えていくので、毎回すべてに目を通すことは現実的ではないでしょう。
そのため、見るべき、学びがある Postmortem をピックアップすることや、内容のサマリを抽出することで、誰でも説明ができるようになるといいと考えています。
今回、@int128 が説明を受けての1行まとめを作ってくれたので、この要領で説明を受けた New Joiner が次への学習教材へつなぐようなことができるといいと考えています。
New Joiner からの感想
それでは7月に入社し、いま現在大活躍している @int128 からオンボーディングについてのコメントをもらって締めたいと思います。
入社してからオンボーディングプログラムが充実していることに驚きました。 Learning Session などで各分野の有識者から専門知識を教えてもらえるので、入社直後から仕事を進めやすかったと思います。 また、私自身もオンボーディングを通して定期的に振り返りを行い、次の New Joiner に向けてオンボーディング体験を改善できたのはよかったです。 フルリモートでの入社はちょっと不安でしたが、Working Out Loud の文化やチーム内外との 1on1 でだいぶ助けられたと思います。 この場を借りて同僚のみなさまにお礼を伝えたいと思います。
おわりに
Quipper SRE Team のオンボーディングを受けてみたい方、改善したい方、まずは入社からはじめませんか。
Quipper では世界の果てまで学びを届けたい仲間を募集しています。
*1:@chaspy の独断と偏見です
*2: Incident Response や SLI/SLO の策定など Culture 面のサポートも含む。
*3:Application Platform
*4:Service / Infrastructure
*5:どれもそれぞれが密接につながっているため、完全に切れて扱えるものではありません。例えば Platform はこれら全てを最適化する土台となる機能を提供します。Site Reliability Engineering の向上のために Cost とのトレードオフを考えることもあるでしょう。
*6:Cluster Autoscaler, Horizontal Pod Autoscaler
*7:Design Doc, Producition Readiness Checklist, SLI/SLO, Postmortem
*8: Quipper はアプリケーションはすべて monorepo と呼ばれる1つの repository に含まれており、Pull Request を作るとアクセスできる環境が立ち上がる
*9:例えば、HPA(Horizontal Pod Autoscaler) 導入以前は手動スケーリングが間に合わず障害を起こしていたこともあった
*10:システム障害を火事に喩えた比喩
*11:そういう Job Title がある。今回の New Joiner であった @int128 さんのタイトル
*12:その少し前に @kuranari さんと @chaspy が 1on1 をした時、それぞれの持ちネタを広いながら調和してつながっていく感じが(音楽にの)"Live Session"だな〜というくだりがあったので、"良きライブ"という表現をしています