こんにちは、スタディサプリで開発をしている @motorollerscalatron です。
私は、5 年前に web エンジニアとしてスタディサプリに join していますが、今年に入ってから、今までの社内(中学講座の開発プロジェクト(通称 tara、最近は 小学講座も加わっています) の web アプリケーション開発に比べて、少し細分化されたドメイン領域である「入稿」のコード開発と運用をおこなっています。今回は、その中でNext.jsを使った校閲出力に特化したマイクロサービスを1つ立てることになったプロジェクトが最近完成したので、そのお話をさせてください。
「入稿」というドメイン領域の切り出し
サービスの話をする前に、今回の話の中で扱う「入稿」、そして「校閲」というドメイン用語を最初に軽く説明します。
下図に示した通り、コンテンツはさまざまなフォーマットで制作され、スタディサプリのシステムで扱うことができる専用の形式で CMS にアップロード(入稿)されています。 このコンテンツ制作の過程の中で、学習コンテンツとしての内容の正しさを担保するため、社外の専門家にコンテンツの内容をチェックしていただくフェーズがあり、それを「校閲」と言います。

これらコンテンツ制作に関わる、CMS や CMS に付随するツールの開発・運用・保守を担当しているのが、私が所属するtara-contents-nyuko-devs(以下 nyuko devs)です。
コンテンツとシステムの繋がりに関すること全般を、社内では「入稿」と呼ぶことがあり、そこから名付けられました。
「入稿」というドメインを、tara 開発部内で詳細ドメインの一つとして切り出し、nyuko devs チームが発足されたのは、わりと最近のことでした。このチームは入稿業務に関する各種 CMS の技術的な側面からの開発・運用・保守を行うことになっています。2022 年の tara のローンチのタイミングから、校閲の必要性とシステム的なソリューションは、当然視野に入っていました。
長年の既存システムでは、入稿のツールは社内で公開される管理画面の形で提供されていました。管理画面型で運用するうちに発覚していた運用と拡張性の問題に対する反省から、 後発である tara プロジェクトでは、コンテンツ管理の目的でこのような管理画面自体を開発する代わりに VScode のプラグインとして提供されるプレビュー画面を用いたり、学習画面に出される問題コンテンツそのものを構造も含めて GitHub 管理にすることで、開発・運用コストを抑えるようにしました(GitHub 画面が提供する各種のバージョン管理インタフェースもコンテンツ運用のユースケースとマッチしていました)。 ドメインの特性上、チームの管轄となるサービスなどのコードベースの境界線も独特となっています。主要サービスの開発チームでは、サービスごとにきっちりチームの担当が分かれやすい傾向がありますが、nyuko devs チームでは、校閲プレビュー機能のような独立したサービス以下であることもあれば、学習画面フロントエンドの開発チームとオーバーラップする部分があったり、という面白みもあります。
なお、一般的に「校閲」というと、紙で印刷するものに対する修正指摘のような形でその中にフィードバックを含めていく編集作業部分も含めて考えられるかと思いますが、今回システム的に話すのは、この校閲の出発点となる学習画面出力をキャプチャして PDF 出力を行うところ、に焦点をおくこととします。
なぜ新規校閲出力システムを作ることになったか

上の図は、既存の校閲出力システムの概略フローです。
- (校閲を行いたいユーザーが tarako (Jenkins) job を実行。
- tara-content が Puppeteer を動かして tara.yml 情報を tarako-view に渡す
- tarako-view が受け取った情報を元に描画される (Puppeteer は描画待ち)
- 描画されたのを確認した後 Puppeteer が Page.PDF() を使って画面のスクリーンショットを撮る
- 生成した PDF 群を zip 圧縮し、 S3 へアップロード
- 実行結果は Jenkins ログとして出力
tara-content は入稿ドメインに属する別の既存サービスです。ここでは、yaml を input すると、それを描画に必要な HTML に変換してくれているコードを持っている状態でした。
学習画面の問題コンテンツの yaml ファイル (以下、 tara.yml と表記 ※) は、前項の図で示した通り、学習問題コンテンツの CMS としての GitHub のリポジトリ上のデータとして登録されており、プログラム側で利用する際には、 @octkit/rest のライブラリを使って取得を行うようなコードになっています。
※ 学習問題コンテンツは厳密には yaml ファイルは構造上の一部で、リポジトリには講座・講義などの階層を表現するために別のファイル構造も含んだ形でリポジトリに登録されています。GitHub のインタフェースは、もともと差分確認やコード検索性には優れていて、当然バージョン管理もできるので、こういった管理には便利である一方、ある種の情報はなかなか検出しづらかったり、CI との相性が良くない差分、というのも運用の中で、発覚してきました。そちらはまた別の機会にお話させていただこうと思います。
新規の tara 校閲出力システム改善というテーマは、前半期から構想があったものの、今期リソースをあてることには理由がありました。
理由その1:既存校閲出力機能を仕上げたとき、理想的な形ではなかったこと
ひとつは、既存の校閲出力システムがいくつか構造上の問題を抱えていたことです。Puppeteer の専用メソッド( [Puppeteer Page.PDF()] ) こそ既に使っていたものの、既存学習画面表示コンポーネントを再利用した最低限の工数でエンハンスしてプレビューのエンドポイントとして振る舞うように実装していたため、特に縦書き(国語)のコンテンツを扱う際に、本来画面では横スクロールになって出るものに問題がありました。

当時は、残り時間リソース的な問題から、この横に長い出力をページ横幅に収まる形で切り分けて縦に並び替えなおしたものを PDF 化することで解決していました。 この時、通常の横書きのテキストでのコンテンツでは、ちょうどブラウザで見た時そのままの感じで、横幅が固定された状態で、中身が増えるごとに縦に伸びていく形で自然に PDF としてキャプチャするので、動作に問題はありませんでした。その一方で、縦方向に切れ目の存在する PDF 形式にしたとき,ページの境目に文字が来てしまうことがありました。これらの一時退避策としては、軽量なエンハンスとして「画像出力と PDF 出力を選択可能にする」「出力の倍率指定」などを入れましたが、根本的な解決は難しく、また、小手先で修正を入れることで別の不具合要因を生むこともありました。

理由その2:タイミング
もうひとつは、需要的なタイミングとこの課題の解決のためのリソース確保のタイミングでした。入稿チームが発足したのは今年の初めだったのですが、発足した当時は年度末と重なり、コンテンツ制作の繁忙期にもあたっていたため、この手の開発系かつ大きめの案件より、運用ベースであがってきているシステム的な問題を解決するほうに注力していました。4 月を超えると、そういった課題は落ち着く一方で、最近リリースのあった小学コンテンツのリソースに向けて大量に入稿を行うことが予測されました。そういった中、何回か保留課題としていたこの校閲出力システムの改善を行うタイミングは今が効率が良い、ということになり、チームのカンバン上の PBI issue の1つとして、扱うことになりました。 この時、既に問題の複雑度が他の関連開発案件により垣間見えていました。「入稿ドメインの中でも、特に既存学習画面コンポーネントのレンダリング思想や構造の理解が必要である」「Next.js に関する知見・試行錯誤が必要になる」といった観点で、厳密に nyuko devs チーム所属ではないのですが、フロントエンド開発で活躍している @indigolain さんの力を大きく借りることになりました。
実際の開発エピソード
各コンポーネントの設計として視野に入れたこと
Ver1

上記は Ver1 のシステム図となります。(※ yaki-tarako というのは今回校閲 PDF 出力を行うサービスについて開発部内でつけた通称のようなものです )図にもありますが、アクションの順番は
[トリガー] (校閲を使いたいユーザーが yaki-tarako (Jenkins) job を実行。
- (yaki-tarako Jenkins job) content_code と対象 branch 名をリクエストパラメータに乗せる
- (yaki-tarako-view-endpoint) content_code と対象 branch(*1) を元に GitHub から yaml を取得
- (tara-content)(※2) tara.yml を元にコンテンツ描画に必要なデータを取得してくる
- (yaki-tarako-view-endpoint)描画に必要なデータを component に渡す
- (React) ReactDOM の
renderToStringで HTML String へ変換 - 変換した HTML string を画面に描画
- (yaki-tarako Jenkins job) Puppeteer ライブラリの PDF メソッドで画面 PDF として出力したものを job 内で保存する
- 校閲を使いたいユーザーは job が完了したら保存された校閲 PDF を取得する
としていました。
(※1) 先で述べていたように、 コンテンツの管理自体を GitHub で行っている関係で、校閲出力を出すときは master のものではなく、それぞれ作業者が作っているブランチの中で登録している yaml を校閲対象とする必要があります。
幸い、初期開発時に既に renderToString を使ってテスト実装をしたコードが残っていました。新しい実装によって、既存システムで存在していた諸問題とどの程度干渉するのか?どの程度同時に解決するか?を見てみたいのもあって、まず、この延長で実装を行って、どう動くのかを試していきました。
しかしながら、、、
この形で実際に実装していくと、いくつかの問題がありました。
- content_code はキー情報であって、実体でない:GitHub のリポジトリへ問題データをとりにいく時に、content_code を渡すことで問題データを fetch しにいく時に find, fetch という2段階になり冗長になる
- css 外部ファイルの参照:
renderToStringを使っていることで、数式の表示であったり、装飾などに使う一部の外部参照の CSS に問題があった
1 つめは、当初 URL パラメータになることを前提として考慮して、それなら URL が簡潔な長さ・表記になるといいだろう、という思想から設計したものでした。ですが、 @octkit/rest が提供しているメソッドを組み合わせて特定コンテンツを取得する部分については id をキーにした設計としてしまうと、ほしいのは1つのデータなのにまずレポジトリの全体のデータを取得しなければならず、さらに実際のデータの中身は条件で見つけた yaml ファイルの中身を取得するためにもう1度 fetch を行う、という形になって、あまり効率がよくないことがわかりました。
2 つめは、これは実装をしてみないと分からなかった部分になるのですが、一部の問題を表現するような CSS に関し、外部ベンダーが CDN 経由で CSS を提供し(たとえば、数式表示に使う KaTeX のようなもの)、さらにその CSS の中から画像が参照される、といった組み合わせがあったときに、 renderToString が思ったようにパスを解決をしてくれずに、思った通りにレンダリングされない(あるいは、問題に対応する形でファイルや実装を加えていくうちに、思っていたフォルダ設計より複雑化していく)、といった問題が発生しました。
Ver2
次のバージョンでは、 Puppeteer が見にいくエンドポイントで Next.js の Server-side Rendering (SSR) を使うようにしました。
Ver1 でわかったパラメーターの修正も含め、Ver2 は以下のようになりました。
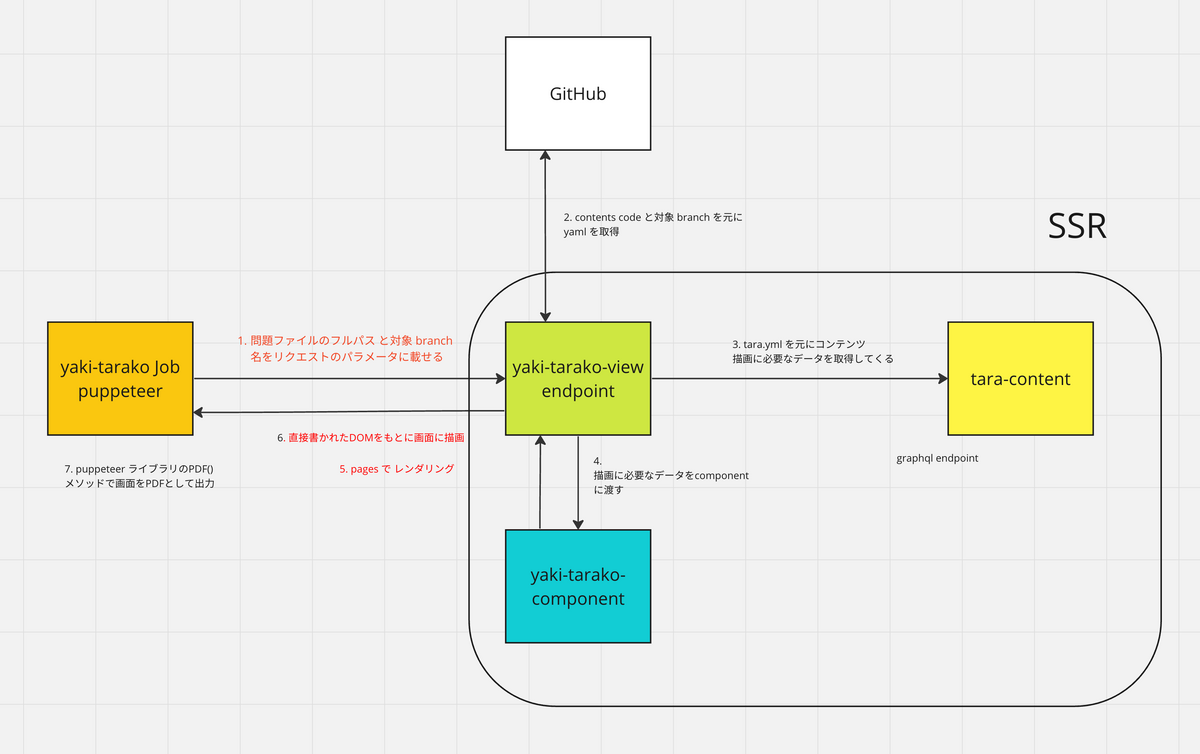
[トリガー] (校閲を使いたいユーザーが yaki-tarako (Jenkins) job を実行。
- (yaki-tarako Jenkins job) 問題ファイルのフルパス と対象 branch 名をリクエストパラメータに乗せる
- (yaki-tarako-view-endpoint) content_code と対象 branch を元に GitHub から yaml を取得
- (tara-content) tara.yml を元にコンテンツ描画に必要なデータを取得してくる
- (yaki-tarako-view-endpoint)描画に必要なデータを component に渡す
- (Next.js) pages でレンダリング
- (yaki-tarako Jenkins job) 直接書かれた DOM をもとに描画されが画面を、Puppeteer ライブラリの PDF メソッドで画面 PDF として出力したものを job 内で保存する
- (yaki-tarako Jenkins job) 生成した PDF 群を zip 圧縮し、 S3 へアップロード
- 校閲を使いたいユーザーは job が完了したら保存された校閲 PDF を取得する
この場合、リクエストパラメータはリポジトリ内でのフォルダ階層も含めた上でファイル名を渡す形となりました。若干長くはなってしまったのですが、Next.js の pagesとの仕組みと相性は良いように感じました。 (例えば、 /[branch]/[filepath].tsx のように明示的なパラメタ指定をソースコードのファイル構造としても残すことができること、などです。) さらには、これにより、開発途中のデバッグ、動作確認もブラウザで直接 URL を叩くような形でアクセスができることもメリットでした(エンドポイントのパス設計は、外部公開されるものであると、直接見せていいような値なのかなどの別の観点を考慮に入れている必要がありそうですが、今回のものは内部限定と考えて良い)。
設計として責務がクリアになったのも収穫でした。以前は job と tarako-view がお互いの情報を知っているような状態でコードとして少しわかりづらかったという反省がありました(例:既存の view のコードに job 側が Puppeteer で探そうとする 描画 wait のためのセレクタを入れていて、job はそのセレクタ文字列が存在していることを期待していた点、等)。新規の yaki-tarako-view は自身に渡されたパラメータで SSR するという構造にしたことにより、Puppeteer はページのコンテンツを知らなくても、コンテンツに飛んでいけば良い、という形になりました。
思わぬ落とし穴
この状態で、style の問題は解消、ブラウザでエンドポイントを見にいってみても、出力は予想した通りとなるようになりました。 ところが、Puppeteer の仕組みを使って PDF 出力をすると、なぜか縦書きコンテンツが複数ページ分が小さく1ページ内におさまって、出力される形になりました。 PDF の形になった状態できれいに出すことが本題なので、これではまだ未完成です。

まずは、この問題に近い現象を、色々既存のバグ起票や Stack Overflow などから探り当てようとしました。挙動の切り分けをする上で(Puppeteer が使うヘッドレスブラウザは Chromium のはずで、PDF() メソッドが出すものも基本的には普段私たちが使っている Google Chrome ブラウザと同じになるだろうと、)Google Chrome で見たエンドポイントの内容を 「印刷」「PDF 出力」として比較してみたり、もしてみましたが、なかなか手がかりが見つからず。
そんな中、私の調査記録の中で観点が全く抜けていたものを、 indigolain さんが見つけてくれました。
「Puppeteer のバージョン最新でしたっけ」
確認してみると、Puppeteer のバージョンが現行最新からだいぶ下のメジャーバージョンであることがわかりました。そしてさらに ミドルウェアアップデート系の管理 issue を検索すると、起票はされていたものの、複合的な問題から様子見を行なったまま pending 状態になっていた未解決のままだったことがわかりました。早速対応、このタイミングでバージョンを上げるのは、既存の校閲出力機能の保証も行う必要がある関係で、思った以上に工数を吸い取られてしまいました・・。が、結局、丁寧にバージョンを上げていくと、あるバージョン以降で、Puppeteer が期待通りの挙動をすることがわかり、ついに、縦書きもきれいに複数ページに分けて表示するような理想の形に達することができました。

SSR のために独立したマイクロサービスを立ち上げる
なんとか、ここまで設計通りに実装ができました。
最後は Next.js の SSR で独立したエンドポイントにするために、校閲用出力の view エンドポイント部分をマイクロサービス化することになります。
私たちの tara 開発チームでは、他にも小さな目的に応じたマイクロサービス立ち上げがあり、直近では小学講座リリースの目玉となった手書き認識機能も、直近で登録されたマイクロサービスとして monorepo となったリポジトリの中で、参考用に確認できる状態になっていました。
私は、このサービス立ち上げフェーズをほとんど不確定要素のない定型作業のように見立てていました。ある程度新規にマイクロサービスを立てるときに共通で必要になるような設定、
- 新規サービス対応分の Kubernetes の rollout, service 設定追加
- ingress リソースの追加
- reverse-proxy に関する設定
などは、もともと汎用的にチェックリスト化できていたものについては指示を受けつつ、ファイルを揃えていくことができたものの、先に述べた図のような新しい設計にしたことで変化していたものとして、もう 1 つ、見落としていたものがありました。・・それは、コンポーネントから学習コンテンツの GitHub リポジトリを参照するときの認証のための設定です。従来版では、学習コンテンツの GitHub リポジトリからの実取得まわりを担う tara-content の中からの呼び出しだった処理が、 新サービスのコードそのものからの呼び出しになっていたので、コンポーネント同士のたどるルートが変わっていたのでした。
弊社の SRE チームは、開発チームが自立して自チームのオーナーシップの持つサービスの IaC 部分も含めて拡張を任せてくれる一方で、相談にも気軽に乗ってくれます。SRE とのコミュニケーションを重ねていった結果、今回の認証部分には GitHub Apps として新しい登録を行うことにしました。権限上、 GitHub Apps の登録と ID の発行は SRE に依頼して行い、私は発行された ID 情報を使って コンテンツの fetch 処理部分を書き直しました。
以下、アプリ側の簡略化したコードを示します。
Octokit.js 経由での GitHub Apps 認証をする場合、
import { Octokit } from '@octokit/rest'
const { GITHUB_ACCESS_TOKEN } = process.env
const octokit = new Octokit({
auth: GITHUB_ACCESS_TOKEN,
})
const result = await octokit.repos.getContent({
owner: REPOSITORY_OWNER,
repo: REPOSITORY_NAME,
path: filePath,
)}
BEFORE: @octokit/rest での直接の呼び出し
に比べて、
import { Octokit } from '@octokit/rest'
import { createAppAuth } from '@octokit/auth-app'
const { APP_PRIVATE_KEY, APP_ID, APP_INSTALLATION_ID } = process.env
const octokit = new Octokit({
authStrategy: createAppAuth,
auth: {
appId: APP_ID,
privateKey: APP_PRIVATE_KEY,
installationId: APP_INSTALLATION_ID,
},
})
await octokit.rest.apps.getAuthenticated()
const result = await octokit.rest.repos.getContent({
owner: REPOSITORY_OWNER,
repo: REPOSITORY_NAME,
path: filePath,
)}
AFTER: Apps としての認証 を挟む
のような形になりました。また、先頭行の process.env から分割代入している内容も増えています。インフラ側でも、発行してもらった Apps 用の ID は環境変数経由でとってくるのですが、これも実行環境ごとにとれるようにする必要があるので、新サービスの Kubernetes Kustomization 設定に、 新しい configmap を設定することになりました。(※)
結果、アプリ側のコード部分には、前のコードとそれほど差分ない形でこのアプリに必要な権限を明確にコード上に表現することができるようになりました。
一度疎通確認ができた後は、サービス自体は想定通りに動くことが確認できました・・!
※ ここではさらっと書いてしまっていますが、実際は、色々試行錯誤していました。私自身が GitHub Apps という概念自体にあまり馴染みがなかったのも一因かもしれません。SRE 側からは、既に使用しているサンプルコードなども提供してもらいました。そして、1つ1つのオペレーションがうまくいっているかをログに出し、時にはペアプロで「開発コードのブランチをきちんと指しているか」など指差し確認しながら、「ここまでは正しく通っている」をたどって、最後まで通った・・という感じです。
まとめ
以上、本稿では、新チーム発足のドメイン的な文脈と、その中で担当した開発のエピソードを共有させていただきました。 後半では、この開発プロジェクトの振り返りについて、もう少し私自身の内省的な観点から、書き記していこうと思います。 最後までお読みいただき、ありがとうございました。