こんにちは。フロントエンドエンジニアの @sakamuuy です。
私たちのチームではエラートラッキングに Sentry というサービスを利用しています。この運用を開始して半年が経過しました。
今回は私が所属するフロントエンドチームでのSentry運用について、苦労したこととその打ち手についてお話したいと思います。
はじめに
エラーを検知し重大なバグなどに早めに気づくことは、Sentryを運用する一つの目的だと思います。
そのためには未解決のエラー件数をなるべく少なくし、発生したエラーを監視できている状態を保つことが必要だと考えています。この状態を保てるように運用で工夫していることについてお話します。
チーム
チームでの運用についてお話する前に、私の所属しているtara学習コアチーム (taraとはスタディサプリ中学講座のリニューアルプロジェクトの通称です) についてお話します。
tara学習コアチームは学習画面と呼ばれるユーザーが実際に学習する画面の開発や運用を担当しています。
この学習画面では動画や音声再生など動作が不安定になりやすいUI要素が多く実装されており、フロントエンドのエラーのほとんどがこの学習画面から発生しています。
そのため、tara学習コアチームがフロントエンドのSentryの運用もメインで担当しています。
体制
tara学習コアチームには現在開発者が6人在籍しており、そのうちの5人でローテーションを組んでSentryの運用を担当しています。
ローテーションの内訳は前週の金曜日にSlackに自動投稿されるようになっています。
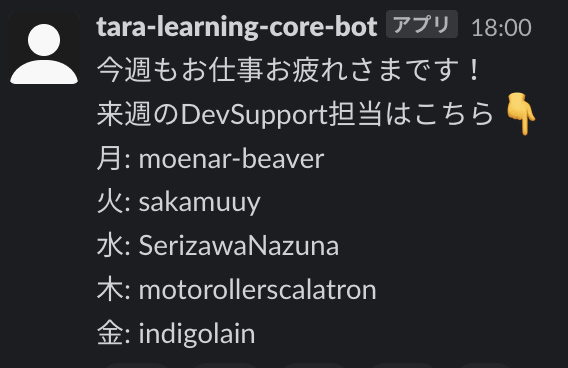
この投稿に沿って毎日のSentry運用担当がアサインされています。*1
作業内容
日替わりのSentry運用担当の主な作業はSentryに新しく通知されたissueのトリアージになります。 Sentryにエラーが通知されるとSlackの特定のチャンネルにSentryへのリンクとエラーが投稿されるようになっています。
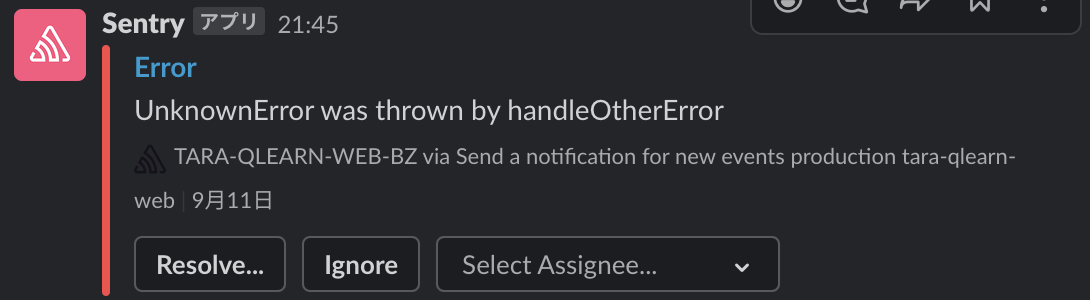
私のチームではこのエラーを4つの対応にトリアージするところまでをSentry担当者が対応し、対応が必要なissueについては別途対応する、という運用になっています。
トリアージの分類は以下のようになっています。
1. 既存のissueとのmerge
2. ユーザー影響がないものなどはignore
3. Bugなど対応が必要なものは、担当チームにメンション・相談
4. わからない場合はチームで相談
また、トリアージ済みのものについてはわかりやすいように、Slack上でスタンプを付けるようにしています。

運用してみてからわかった課題
つづいて、半年以上の運用の中で見つかった課題とそれに対する現状の打ち手についてお話します。
課題1: 日々の運用作業の負担
トリアージするまでの作業とはいえ、多いときは一日に10~15件ほど通知が来ることもあり、一日のトリアージの作業時間が1hほどかかることもあるため、作業担当者への負荷が大きいことが度々チーム内で話題に上がっていました。
断続的に続くエラー調査の負担と、自身が請け負っているメインのタスクとでコンテキストスイッチもあり、メインのタスクを上手くすすめることができない時があることが課題となっていました。
この課題について、まずはエラーを整理して通知される件数を減らすようにする、という打ち手を立てています。
課題1に対する打ち手
運用の中で調査し、いくつか無視してしまって問題ないエラーがあることがわかっていました。これらのエラーをそもそも通知されないようにすることで、トリアージの件数を減らすようにしています。
具体的な方法としては、Sentryには ignoreErrors というオプションがあり、文字列もしくは正規表現を渡すことで通知するエラーをフィルタリングすることができます。
https://docs.sentry.io/clients/javascript/config/
現在プロダクトでは下記のような設定をしています。
ignoreErrors: [ 'Network Error', 'Failed to fetch', 'Load failed', 'No error message', 'NotSupportedError', 'Unexpected token', 'NotAllowedError', 'safari-web-extension://', ],
例えば、Network Error 系のエラーであればユーザーの回線状況が原因の場合が多く、たとえバックエンドでエラーが起きていたとしても、バックエンドのSentryで検知できるため、フロントエンドのSentryでは無視して問題ないと判断しています。
この他、ユーザー影響のないものや、利用している動画再生ライブラリからのエラーやブラウザの拡張機能などの、チーム内で対処することのできないエラーについて通知しないように設定しています。
結果(全てがこの打ち手によるものではないと思いますが)、最近では多くとも一日に5件ほど、少ないときは通知されるエラーがないほどまで落ち着かせることができました。
課題2: 調査の難しいissue
いくつかのissueは原因の特定が難しいものがあります。
調査に長く時間を使っても原因がわからず、結局徒労に終わってしまうということが度々あり、チームとしてSentryを運用すること自体このコストと見合っているのか、という話題も上がってきてしまっている状態となってしまっていました。
全てのissueの原因特定をすることは難しいのですが、少しずつ情報を増やす努力をしたり、他ツールと合わせて調査するなどの対応をしています。
課題2に対する打ち手
Tags
情報を増やすためにSentryのTagsを利用しています。
Tagsはキーと値の文字列のペアになっていて、Sentryのイベントに対して情報を付与することができる機能です。
tara学習コアチームではこの機能をエラーがどこから発生したものなのか、ユーザーにどの程度影響を与えているのか、などに利用しています。具体的には下の画像ようなTagsになります。

例えば、from: video-player のTagが付与されている場合、このエラーは動画再生に使っているライブラリからエラーが発生していることがわかります。他にも from: webview/ErrorBoundary の場合、ユーザーにはエラー画面が表示されてしまい、ユーザーのやりたかった操作ができていなかったことが想定されるため、このエラーの調査優先度は高くなる、といった判断がしやすくなります。
Tagsはソースコード上ではSentryにエラーを通知している任意の箇所に記述することができます。
Sentry.captureException(error, { tags: { from: 'webview/ErrorBoundary', }, })
また、このようにTagsを付与しておくと、SentryのUIからも付与したタグを条件に絞り込み検索なども行えるようになります。
Datadog
Sentryのissue上からは、ユーザーがエラー発生前どういった操作をしていたのか、エラー発生後問題なく操作続行できていたのか、が読み取れない場合が多くあります。その場合、ユーザーの操作をより詳しく調査するため、Datadogも合わせて利用しています。
Sentry上のissueからはUserIdやSessionのIPアドレスなどが取れるため、そこからDatadogの対象セッションを見つけて調査する、という対応をよく行っています。
Errorの情報を増やす活動
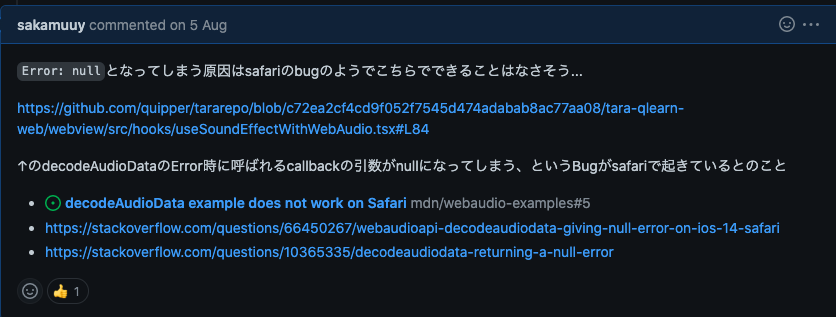
Sentry上のissueを見ても何わからないようなissueの場合、そこから情報を広げることができないか検討しています。
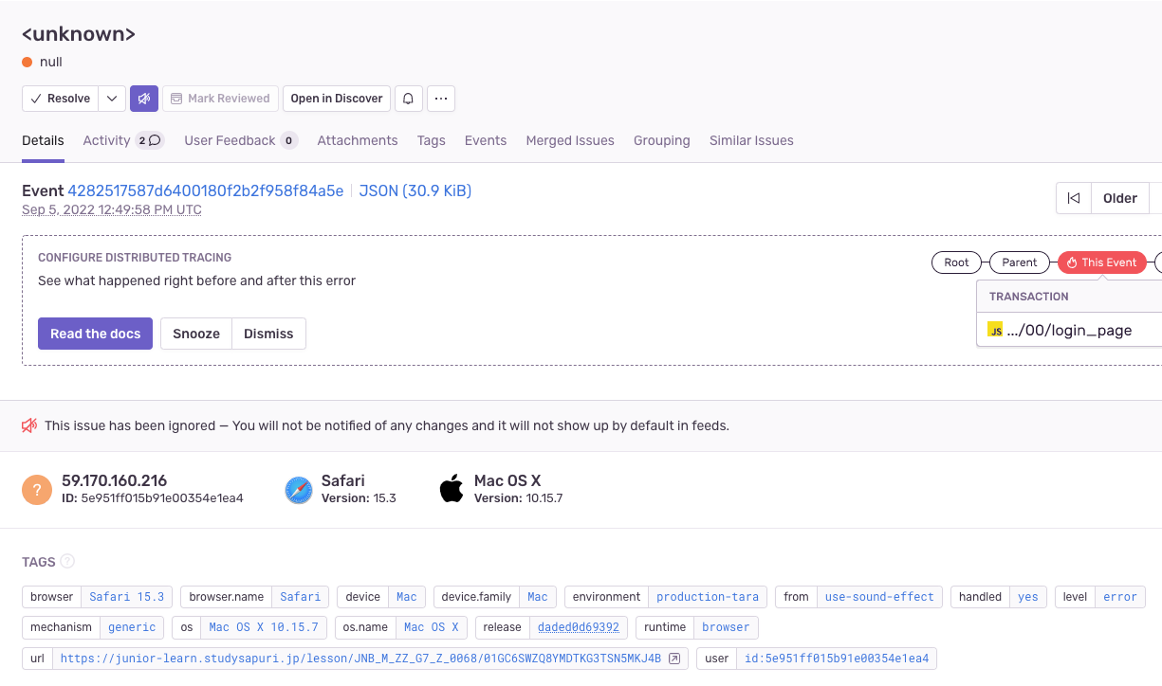
例えば上のようなissueの場合、Sentryに通知されているエラーメッセージからは何も読み取ることができませんでした。
ただ、fromTagがついていることから、use-sound-effect という共通関数で起きたエラーだということのみがわかっている、という状況です。
こういったエラーの詳しい状況がわからないような場合には、エラーの情報を増やすようなissueをGitHub上に作成し、改めて対応しています。
全てのissueの原因を特定するのは難しいですが、他ツールと組み合わせたり、少し時間を取ってより詳しい調査や情報を増やすような対応をして、未解決のエラーを減らしていくように対応しています。
おわりに
最後に、活動の振り返りとして、ご参考までに直近三ヶ月のエラーイベント件数推移のグラフになります。
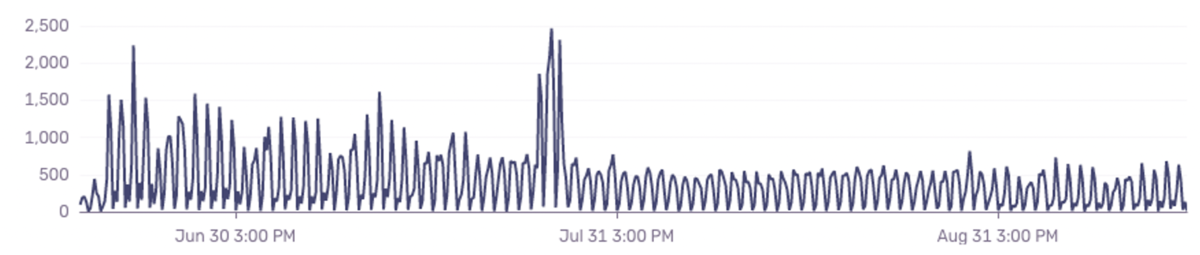
局所的に件数が跳ね上がっている箇所はありますが、全体的には落ち着いてきているように見えます。
Sentryなどエラー監視の運用は終わりがないもので、運用のコストは一定発生するものと考えています。
コストは払いつつも、運用を最適化して継続していきたいと考えています。未解決のエラーの件数が増えてしまった結果、見きれなくなってしまい、重大なバグを見逃してしまっていた、ということがないように、Sentryの健全な状態を維持して、プロダクトの改善に役立てていきたいです。