こんにちは。@chaspy です。プロダクト開発部の技術戦略グループのマネージャをしています。
技術戦略グループでは、日頃開発する上での課題の投げ込みや議論、解決するための計画をボトムアップで行っています。技術戦略グループの活動については過去のアウトプットもご覧ください。
また、本稿のテーマである、組織やシステムの状況を把握するための Fact 収集については技術戦略 DevOps WG が担当しています。以前発表した資料もご覧ください。
このように、技術戦略グループではエンジニア1人1人が課題だと思うことを表明、宣言し、その課題をトリアージすること、および課題を評価するための Fact の発見・提供を行う仕組みが組織としてボトムアップで行える状態になっています。一方、開発部長として、事業戦略と結びつける形で技術戦略を策定する際には、現場のエンジニアが直面している課題ベースではなく、俯瞰的に状況を判断できるメトリクスが必要です。
この記事では、開発組織の状況をなるべく Fact に基づいて判断するための切り口とその方法を紹介します。開発組織のマネジメントに携わる EM, VPoE, CTO のような方々の参考になれば幸いです。
収集する Fact
以下を収集し、評価を行いました。
- システムの構成要素について
- システムのパフォーマンスについて
- リソース効率性
- 開発組織について
- プログラミング言語・領域別技術習熟度
- マイクロサービス別開発活発度
システムの構成要素について
プログラミング言語比率
我々が提供するプロダクトがどのプログラミング言語で構成されているのか、その比率を把握しました。私たちは monorepo を採用しているため、GitHub で簡単に把握できます。
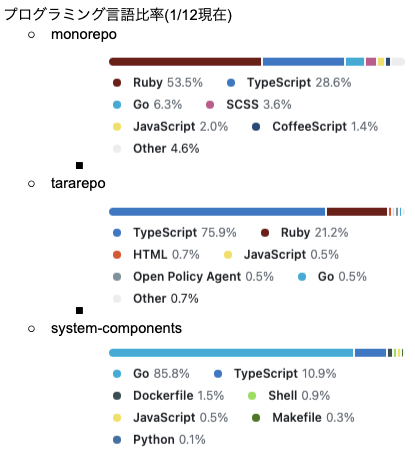
この結果から言えることは以下です
- Backend は Ruby が圧倒的に比率が高い
- 次点として Go
- SRE が管理している system-components は Go が支配的
- CoffeeScript が一定割合存在している
この結果を受けて、以下のアクションを取りました。
- CoffeeScript については今後書かない方針のガイドライン策定*1*2
マイクロサービスごとのプログラミング言語と LOC
前項では monorepo に含まれるコードベース全体のプログラミング言語比率を出しました。別の角度で分析するため、マイクロサービスの単位でも同様の分析を行いました。
取得方法は簡単なツールを書きました。
gh extension としてインストール、実行できます。monorepo 上での実行を前提としており、各ディレクトリごとに言語をパッケージマネージャベースで判定し、LOC を出力しています。*3
結果は以下の通りです。*4
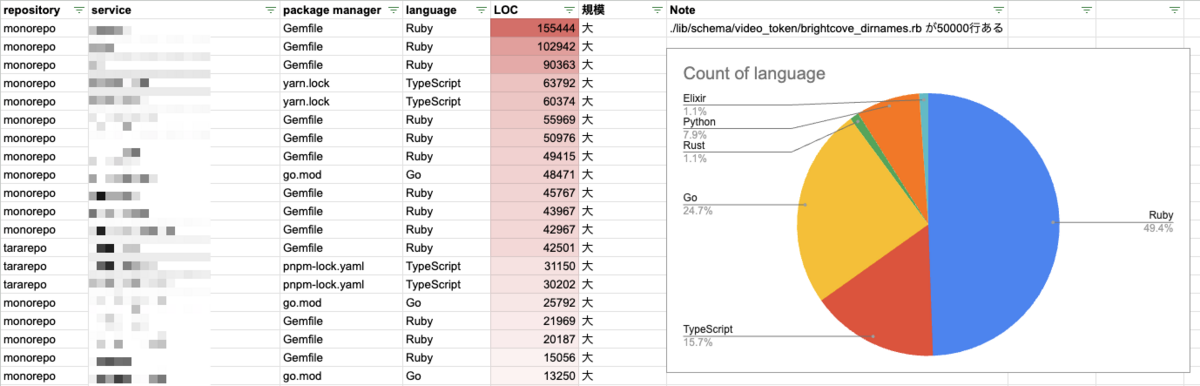
継続的に取得する上で、Spreadsheet だとディレクトリが増えた場合面倒になったので、Datadog に送ることにしました。元々 GHA から Datadog に送る @int128 が作成した send-datadog-action を活用していました。今回のようにサービス単位で一気に送りたいので、csv をインプットにしてもらうよう要望したらすぐに対応してもらえました。最高です。
こんな感じで送っています。
name: metrics / send-loc-to-datadog on: schedule: # 3:00 UTC (= 12:00 JST) Everyday - cron: 0 3 * * * jobs: send-loc-to-datadog: runs-on: ubuntu-latest timeout-minutes: 10 steps: - uses: actions/checkout@v4 - run: gh extension install chaspy/gh-monorepo-stats env: GH_TOKEN: ${{ github.token }} - run: | echo "REPOSITORY_NAME=${GITHUB_REPOSITORY#"$GITHUB_REPOSITORY_OWNER"/}" >> "${GITHUB_ENV}" - run: | gh monorepo-stats > result while IFS=, read -r service_name _ lang loc; do service_name=$(echo "${service_name}" | xargs) lang=$(echo "${lang}" | xargs) loc=$(echo "${loc}" | xargs) if [ -n "$loc" ]; then echo "custom.monorepo.loc,GAUGE,$loc,repository:${REPOSITORY_NAME}, language:$lang, service:$service_name" >> metrics.csv fi done < result env: IGNORE_DIRS: "(省略)" - uses: int128/send-datadog-action@v0.20.0 with: datadog-api-key: ${{ secrets.DATADOG_API_KEY }} metrics-csv-path: | metrics.csv
Datadog だとこんな感じです。いい感じですね。
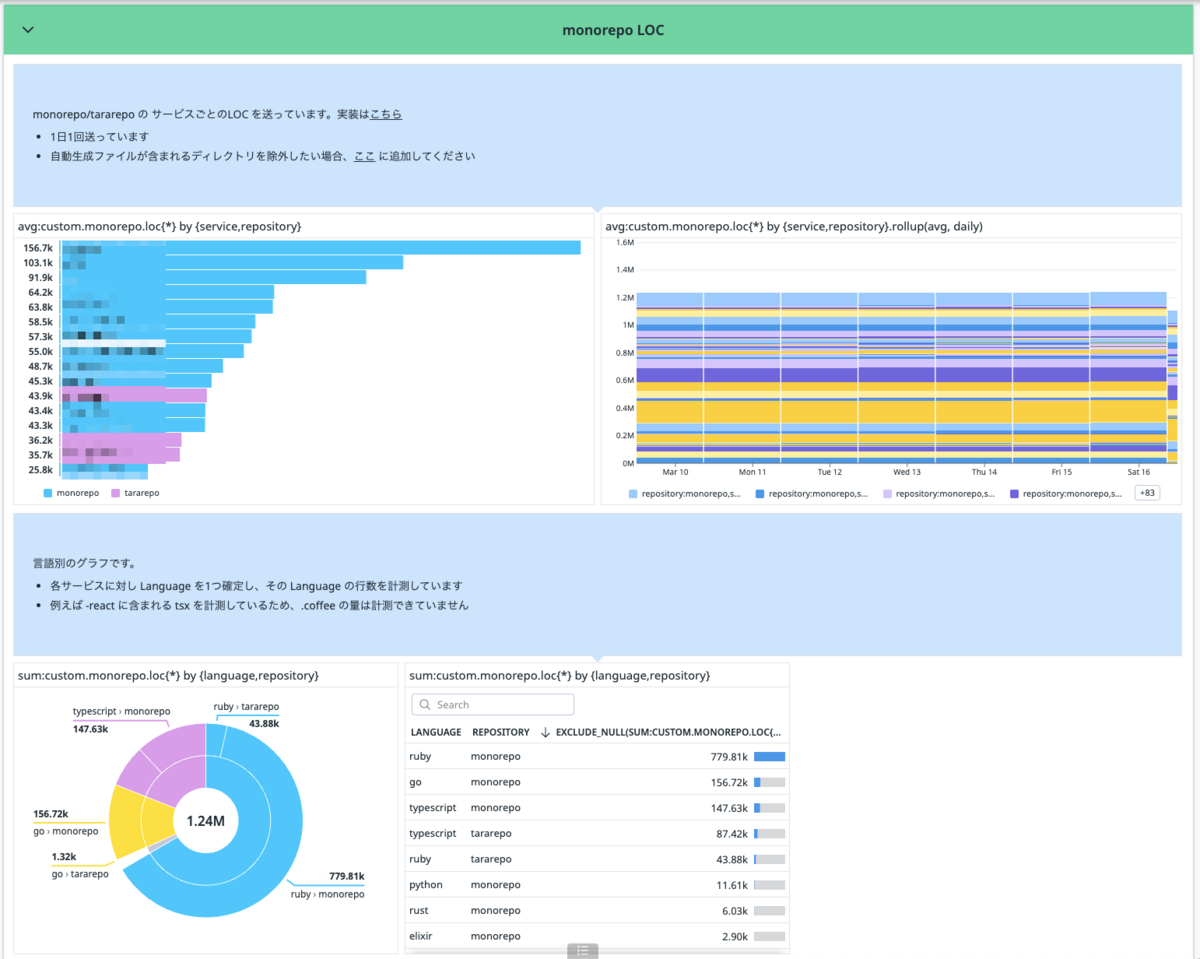
ここでも Ruby が半数であることがわかります。また、このように LOC を出してみることで、感覚で語られている「あのサービスは大きい」「肥大化し続けている」という意見に対して、客観的に判断することができます。
この結果からの直接的なアクションは現状ありませんが、4半期ごとに取得することで、変化を見ていこうと考えています。
EOL を迎えたソフトウェア数
スタディサプリは多数の OSS / ライブラリに支えられています。そしてライブラリのアップデートは定期的に行わないと、将来の改修コストが高くなってしまうリスクがあります。また、セキュリティアップデートに追随するためにも重要です。
これを直接的に取得するのは難しいので、先行指標として「放置されている Dependabot / Renovate PR 数」としました。
取得方法として、簡単なツールを書きました。一言でいうと monorepo を前提とした gh コマンドのラッパーです。
わかりづらい重要な前提があるのですが、弊社の monorepo では PR が作成された際に、変更があったディレクトリ(サービス)を検知し、同名の Label を Danger で付与する仕組みがあります。
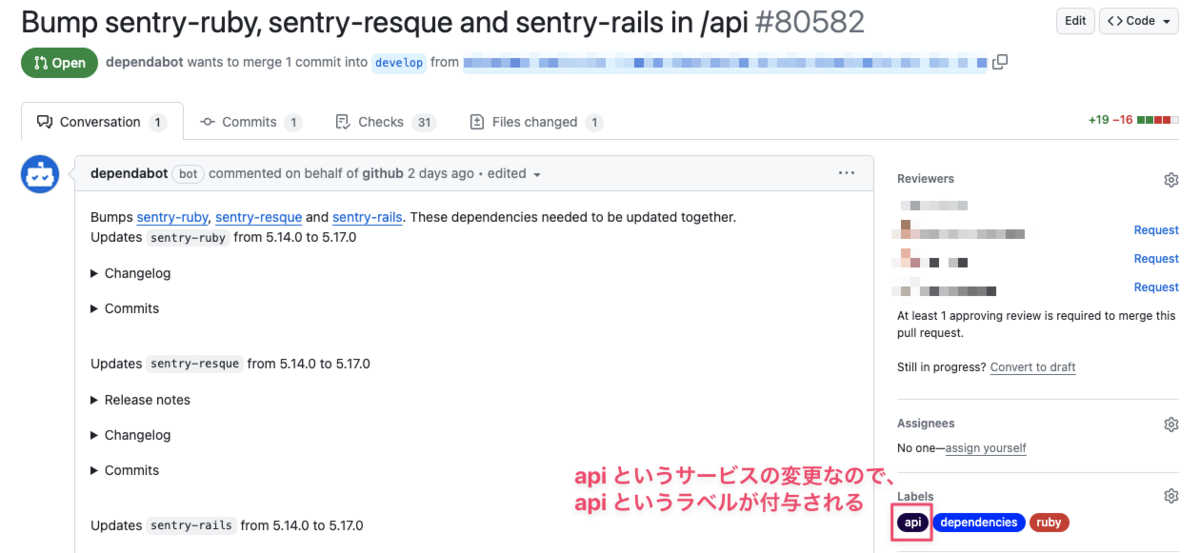
この仕組みを利用して、GitHub 検索で Label で絞り込むことで PR をサービスごとに数えることができます。このツールでは GitHub の検索オプションも指定できるため、author:dependabot と絞り込むことで Dependabot による PR 数を数えることができます。
そしてこれも前述したものと同じ仕組みで Datadog に送っています。こんな感じです。
name: metrics / send-dependencies-pr-count-to-datadog on: schedule: # 3:00 UTC (= 12:00 JST) Everyday - cron: 0 3 * * * jobs: send-dependencies-pr-count-to-datadog: runs-on: ubuntu-latest timeout-minutes: 10 env: GH_TOKEN: ${{ github.token }} steps: - uses: actions/checkout@v4 - run: gh extension install chaspy/gh-monorepo-pr-count - run: | echo "REPOSITORY_NAME=${GITHUB_REPOSITORY#"$GITHUB_REPOSITORY_OWNER"/}" >> "${GITHUB_ENV}" - name: Get dependabot PRs run: | bash metrics/generate_dependencies_pr_count_csv.sh dependabot >> metrics.csv env: SEARCH_QUERY: "author:app/dependabot" - name: Get renovate PRs run: | bash metrics/generate_dependencies_pr_count_csv.sh renovate >> metrics.csv env: SEARCH_QUERY: "author:app/renovate" - uses: int128/send-datadog-action@v0.20.0 with: datadog-api-key: ${{ secrets.DATADOG_API_KEY }} metrics-csv-path: | metrics.csv
- metrics/generate_dependencies_pr_count_csv.sh
#!/bin/bash
AUTHOR=$1
gh monorepo-pr-count --state open --since 2017-09-21 > "${AUTHOR}_result"
while IFS=, read -r service_name pr_count; do
service_name=$(echo "${service_name}" | xargs)
pr_count=$(echo "${pr_count}" | xargs)
if [ -n "$pr_count" ]; then
echo "custom.monorepo-pr-count,GAUGE,$pr_count,repository:${REPOSITORY_NAME},service:$service_name,author:app/${AUTHOR}"
fi
done < ${AUTHOR}_result
Datadog 上ではこんな感じで見れます。
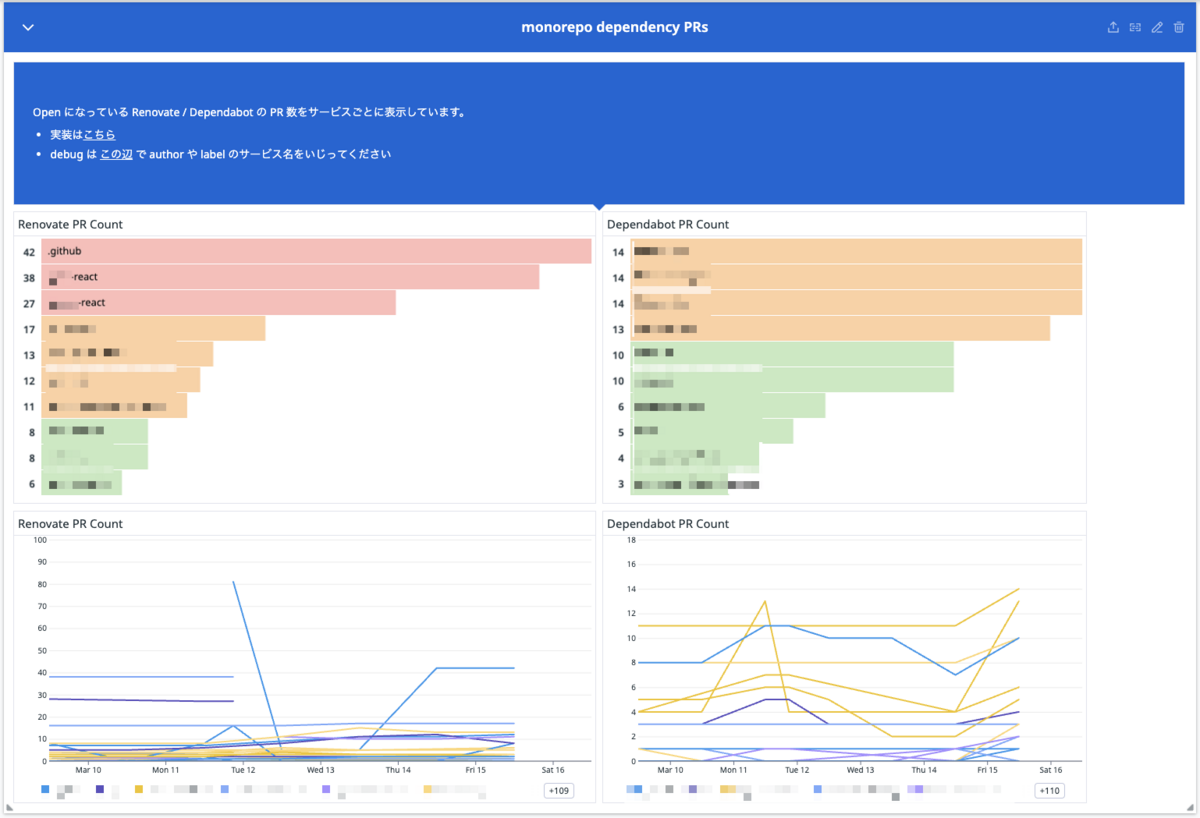
普段から定期的にライブラリアップデートをしているおかげか、大量に溜まってないことがわかります。
また、更新がされないのではなく、メンテナンスが止まっていることもリスクとなるため、dep-doctor を利用し、発見したら通知する仕組みを構築予定です。
システムのパフォーマンスについて
リソース効率性
リクエストしている Compute Resource に対して、どれぐらいパフォーマンスを発揮しているかを定量的・継続的に把握したいと考えました。これは Datadog で出しています。
http request hits / CPU or Memory usage で計算しています。
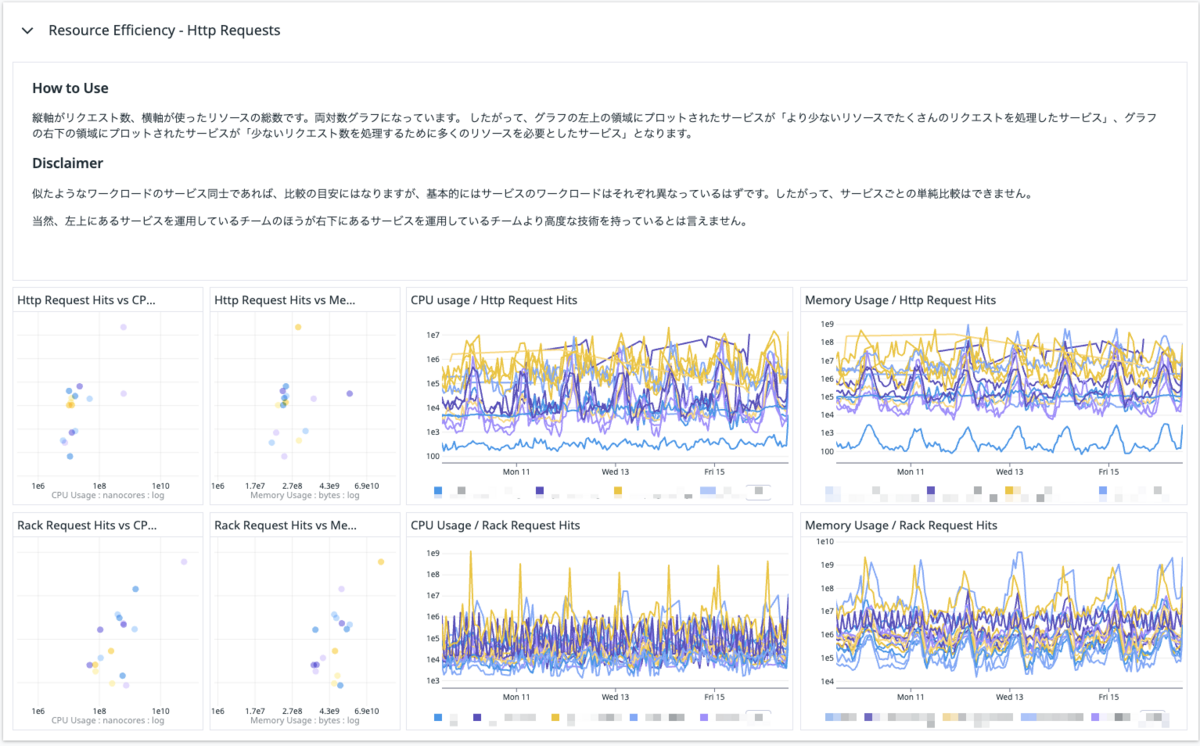
大切なことは Disclaimer に書いてあります。大事。
左側のグラフは対数グラフになっています。上に行けば行くほど大量のリクエストを捌いており、右に行けば行くほど大量のリソースを利用しているということになります。繰り返しますが左上のサービスがえらいというわけではなく、各サービス単位での推移を見ていくことが重要だと考えています。
開発組織について
プログラミング言語別技術習熟度
先ほど利用しているシステムのプログラミング言語の割合を出しました。利用されるコードベースが多いプログラミング言語に対して、習熟度が一定レベル以上の人が多く存在することが期待されます。逆に、いくらコードベースの割合が少なくても、採用言語を使える技術者が1人もいなくなってしまうと事業継続上のリスクになってしまうでしょう。
簡易的に凡例を作成し、Engineering Manager に入力してもらいました。
- 3
- 社内の他の人への教育ができる
- 詳細な仕様を理解しており、未知のリスクに対処できる
- 最新機能をキャッチアップし、それを自組織に活用を推進できる
- 2 1 と 3 の間
- 1 調べながら PR を出すことができる
結果や考察については割愛しますが、各プログラミング言語別のエンジニアの状況分析に役立ちました。
マイクロサービスごとの開発活発度
システムを分析する上で、どのマイクロサービスが活発に変更が行われているのか、あるいはどれぐらいの人数が関わっているのかを知ることも組織の状況を示すメトリクスになります。
これも Renovate / Dependabot の PR 数を計測するツール*6で計測しました。*7
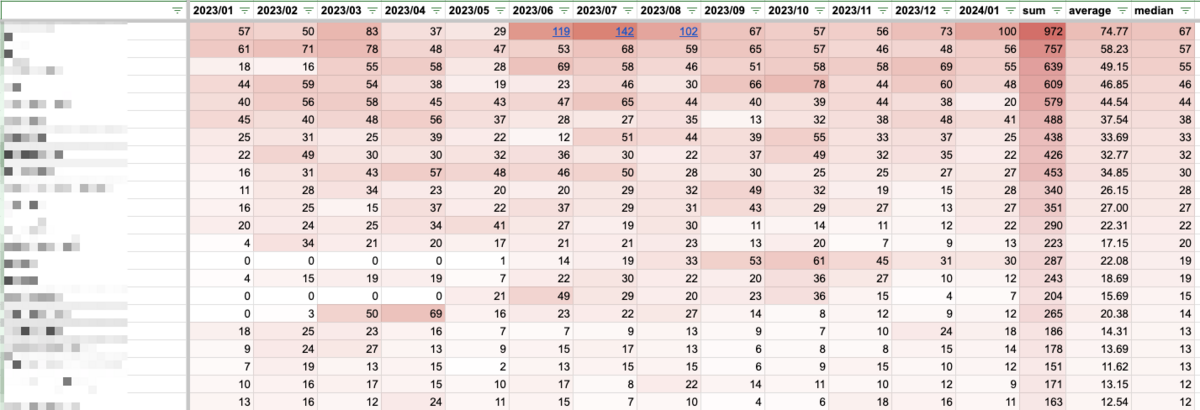
Conditional Format を使ってヒートマップとしました。どのサービスが恒常的に多いのか、あるいは時期的に多いのかを見ることができます。これも四半期ごとに定期的に取得しようと考えています。また、マージされた PR 数は Four Keys のうちの1つのデプロイ頻度や変更のリードタイムの先行指標になる Metrics だと考えます。この観点でも推移を追うと発見があるかもしれませんね。
また、1つのサービスを多くの人が触っている場合、コミュニケーションのオーバーヘッドが多くかかっている可能性があります。Unique Author も出せるようにしています。

月に20人が触っているサービスは多いと言える気もしますし、内部で Module がちゃんと分かれており、それごとにオーナーシップが決まっており、かつ疎結合になっているのであれば問題ないかもしれません。これも絶対的な閾値を見るというより、推移を見ていき、異常の予兆に気づけるようにしたいと思います。
おわりに
様々な角度からシステムや開発組織の定量化を試みました。これにより、感覚的な判断から客観的な判断に変えることができ、また、定量化することで変化を見ることができるようになりました。ボトムアップでの改善活動に加えて、俯瞰的に状況を把握できることで早期に問題の種に気づけるようにしたり、中長期の技術戦略を考えるためのインプットを得られました。
技術戦略について興味がある方は@chaspy_までご連絡ください。話しましょう!
*1:現在フロントエンドは React / TypeScript で大部分が書かれているため
*2:ガイドラインの策定についてはこちらの記事も参照ください
*3:この特性上、マイクロサービスごとに言語は1つであるという前提があります。例えばフロントエンドとバックエンドが同じディレクトリ上にある場合は正しい計測結果になりません
*4:前述している system-components は対象外です
*5:.github 以下は GitHub Actions の更新である。これは Workflow ごとに CODEOWNER を付与することで気づいてもらえるようにしている。
*6:前述したchaspy/monorepo-pr-count
*7:月ごとに特定の Label がついた PR を計測するしています。例えば gh monorepo-pr-count --since 2023-11-01 --until 2023-11-30 というコマンドを実行すれば各サービスごとの2023年11月の PR 数が得られます。