Merry Christmas! SRE Team の @panicboat です。
突然ですが、皆さんはジョブ基盤に何を使っていますか? Jenkins や Digdag、Apache Airflow など多くの選択肢があり組織にマッチするものを選択するだけでも苦労しますよね。 今回はジョブ基盤を Jenkins から Argo Workflows に移行している件について話していこうと思います。
移行前の状況
私たちは Jenkins をジョブ基盤として使っています。Jenkins とは CI/CD に関連するタスクの自動化を行うことができる OSS です。 多くのジョブは Jenkins から独自ツール経由で Kubernetes のジョブを作成し、実行する形でした。 (ただし少数派として Jenkins インスタンス上で実行するジョブも存在していました)
以下は独自ツール経由で Kubernetes のジョブとして実行するスクリプトの例です。
YAML_FILE="job_`date +%Y%m%d_%H%M%S`.yaml" # 汎用的な CronJob のテンプレートから Job の manifest を出力し、 # "kube-job-patcher" という独自ツールで変数を代入することで Kubernetes Job の manifest を生成 kubectl create job -n $NAMESPACE --context "$KUBECONTEXT" --from cronjob/job-template "sandbox-$(date "+%s")" --dry-run -o yaml | \ kube-job-patcher -e DRY_RUN -- yarn sandbox:run > $YAML_FILE # kubectl の Job に限定した簡易ラッパーの "kube-job-runner" を使って状態とログを追跡し続けます echo "=== Running job" kube-job-runner -f $YAML_FILE -n $NAMESPACE --context "$KUBECONTEXT" sleep 30s # このままだと Job リソースが残ってしまうので削除が必要 echo "=== Delete job" kubectl delete -f $YAML_FILE -n $NAMESPACE --context "$KUBECONTEXT" || true
また、ほとんどのジョブは、SRE チームによる自己完結チーム化の方針*1や技術戦略グループによる、サービスやソースコードにオーナーシップをつける取り組み*2によってオーナーが明確になっていました。
こうして振り返ってみると移行を進めやすい状況だったのは非常に幸運でした。
Jenkins の課題
Jenkins の手軽さは非常に便利な反面、私たちの組織ではいくつかの課題を持っていました。 代表的な課題の例として、前述の独自ツール経由でのジョブ実行では以下のようなものがありました。
- Jenkins と Kubernetes で独立して動いているので問題の調査が難しい
- Jenkins ジョブは失敗しているが Kubernetes ジョブは成功になっている場合がある
- Jenkins ジョブでログが途絶えたが Kubernetes ジョブは動いている場合もある
- Kubernetes ジョブが失敗した原因を調べるのが難しい
また、運用面でも以下のような課題がありました。
- Jenkins のアップグレードには多くのリソースと一定の負担が必要であり、バージョンの最新化がしづらかった
- Jenkins インスタンス上の Ruby や Node.js などを手動アップデートする必要がある
- 誰でもジョブを削除できるので監査履歴が残らない
- Google OAuth の groups スコープが運用されておらず権限管理が難しく、Pull Request のレビューを通らずに任意のコンテナを実行できてしまう
- Pull Request を通してジョブの定義を変更できないので不便
- Jenkins の手軽さを優先していたためコード管理のモチベーションが低かった
上記の運用課題のいくつかは解決策があったようです。
- 監査ログを取得 : Audit Trail
- Pull Request を通してジョブの定義を変更する : Job DSL
Argo Workflows とは
Argo Workflows は Kubernetes ネイティブなワークフローエンジンです。
ここでは詳細に説明すると大変なので @makocchi さんによる Slide を紹介しておきます。 理解がとても捗りました。感謝。
移行準備
移行作業をスムーズに進めるため、Jenkins 利用者への案内前にいくつかの作業が必要でした。 また、新規導入にあたり社内レビューが必要だったので併せて実施しています。
Proof of Concept (PoC)
@chaspy さんから助言をいただいて Jenkins を利用している 1チームに協力いただいて PoC を実施しました。 モブプログラミングでいくつかの Workflow を実装し使用感を評価していただき、ここでの成功体験を後述の社内レビューの材料にしています。
社内レビュー
全体に関わる内容なので独断で決めることは好ましくありません。 そのため以下の観点ごとにレビューを実施し導入可否を判断しています。
- 多角的な視点で移行に耐えうるか
- 新規導入なのでセキュリティ面でも漏洩リスクなどがなく安全か
とは言っても枠組みは元々用意されていましたし、過去のレビューも確認できたので必要以上に大変な思いはしませんでした。
Workflow のデフォルト設定
Argo Workflows では Workflow にデフォルトの挙動を設定できます。 私たちはこの仕組みを利用し以下を実現しています。
- Workflow の終了処理
- Datadog に成否の Metrics を送信
- Dead Man's Snitch にチェックイン
- 処理結果に関わらず定期的な実行が行われているか確認しています。
- 処理結果を Slack に通知
- 実行履歴やログの保存
- Workflow の実行履歴は Kubernetes Cluster のリソースとして存在されているだけなので放置すると Cluster の負荷が上がるため、RDS に保存して Kubernetes Cluster から短期間で GC (Garbage Collection) しています。
- ログは Web UI を通して Pod 内のログを参照していますが、Pod が消えると Web UI からログが参照できなくなるため S3 に保存しています。
他にも細かな設定を入れていますが、大まかには上記になります。 この仕組みを使うことで学習コストや運用コストを軽減できたと思います。
CI/CD の整備
名前の通り特に特筆することはありませんが、このタイミングで monorepo のディレクトリ構成を少し検討する必要がありました。 各マイクロサービスは以下のようなディレクトリ構成を採用しているため、通常 overlays 直下が環境ごとに分割されています。 環境と Kubernetes の namespace が 1:1 となっている状態です。
. ├── マイクロサービス/ │ ├── README.md │ ├── プロダクションコード... │ ├── テストコード... │ ├── Dockerfile │ └── kubernetes/ │ ├── base/ │ └── overlays/ │ ├── develop... │ └── production... ...
ですが私たちの利用方法では overlays 直下の環境ごとでも分割する必要がありました。 環境と Kubernetes の namespace が 1:N となるようにしなければなりませんでした。
これはいくつかの案を技術開発戦略を決める横断的な会議体に持ち込み決定しました。 しかしながら複雑度は増してしまったので今後改善したいと思っています。
移行スクリプトの開発
Jenkins では SCM Sync Configuration を使ってサーバー毎に GitHub Repository にジョブの設定を xml 形式でバックアップしています。 今回はこちらを使い Argo Workflows のマニフェストに変換するスクリプトを組みました。
移行を案内してからにはなりますが、機能改善の要望をいただいたり、Bug Fix の Pull Request を出していただくことがあったりと色々と助けていただきました。 これらのような協力のおかげで想定していたパターンのほぼ全てを網羅しスクリプトによる移行は完遂に近いところまでできました。
移行開始
上記のような対応を事前にしていたことにより、通常の開発フローと同等の手順で移行を進めることができるようになりました。
移行の案内
事前に社内レビューが通っていたこともあり、案内自体は何も問題が起こらず身構えてた分肩透かしでした笑。 案内の内容としては作業手順と Q&A、Argo Workflows とは何か、Web UI の使い方、Datadog での監視方法などです。
ここでは @snowfield702 さんによる存在感の強い勉強会資料に助けられました。
移行状況の管理
移行状況は Google Spreadsheet を利用して管理しています。 「ジョブ名/オーナー/移行可否/移行時期/移行状態/備考」と簡単なものですが、定期的に残ジョブ数を Slack で通知することで更新漏れなども防げているのでうまく運用できていると思います。
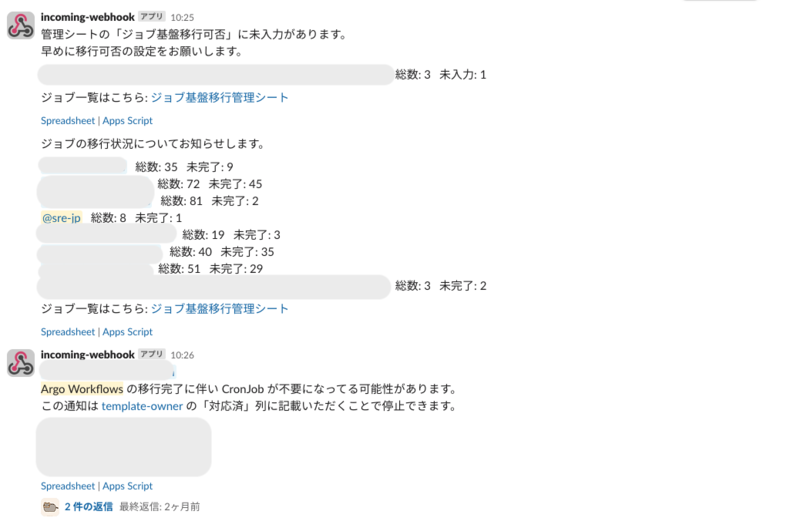
実は移行を案内したタイミングでは管理を忘れていたのですが @hayat01sh1da さんに指摘いただいて救われました。 あのタイミングでの指摘がなかったら…と思い出すだけでも恐怖です。感謝。
Scaffold の開発
これまでやってきたことは既に動いているジョブを Argo Workflows に移行するものでしたが今後は新規追加が必要になってきます。
これは GitHub Actions から手動実行する形で実装し、このような形で Pull Request が作成されます。
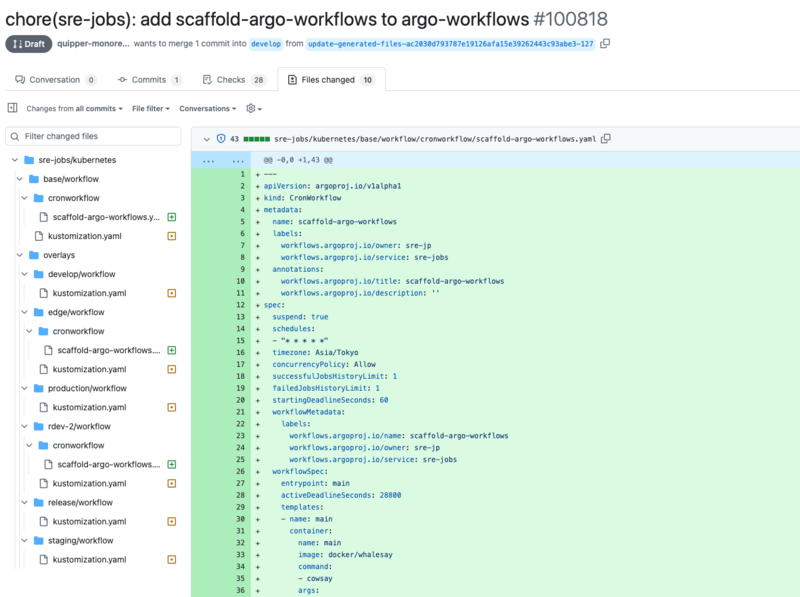
もちろん動いているマニフェストをコピペするのも悪くはないんですが、Scaffold として関連マニフェストの自動追加があるとミスを少なくできます。
新規作成した Workflow のマニフェストのファイルパスを kustomization.yaml に追加するのとか忘れがちですしね。
アンケートの収集
移行の大変さ、Argo Workflows を使ってみて感じた課題など Jenkins 利用者から意見をいただくことができました。 多くの利用者に回答していただき改善の方向性が見えてきたので、これらの意見を元に改善を予定しています。
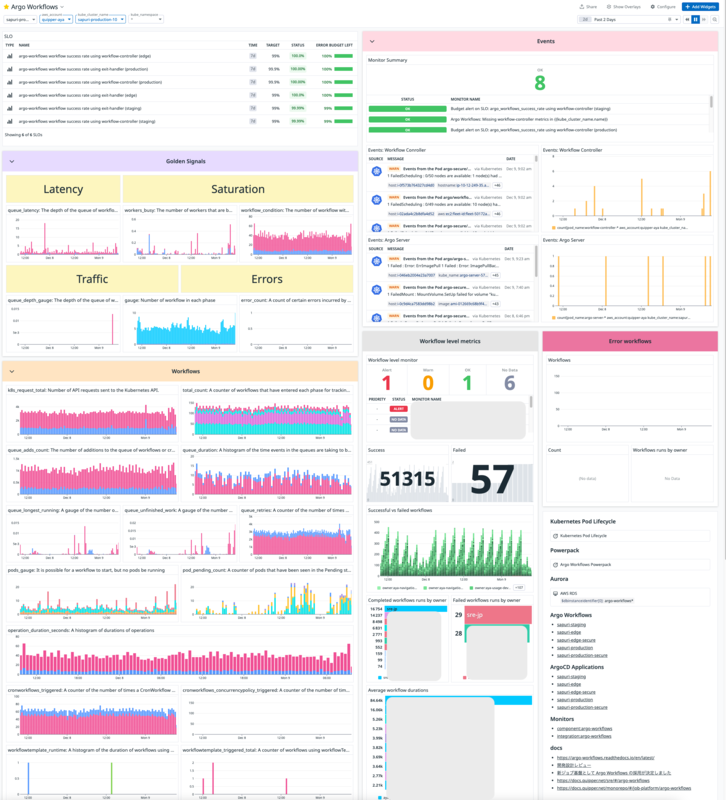
SLO の導入
SRE というロールを持っている以上、Platform の信頼性は担保しなければいけません。 ジョブ基盤としてどんなメトリクスをモニタリングすれば良いか難しいですが、ひとまず以下のような SLO を設定しました。
Workflow の成功数 + Failed の Workflow 数 / Workflow の総実行数
これにより Jenkins 利用者が気にするべきではないエラーをおおよそ拾うことができているので、 これと Argo Workflows から提供されているメトリクスを定期的に味わう運用をして信頼性を担保しています。 Datadog のダッシュボードは以下のような雰囲気です。
移行後に発生した課題
移行が開始され実際に本番運用が始まると以下のような問題点が出てきました。
Workflow の履歴を表示すると Web UI が表示できなくなる
定期実行される Workflow を運用開始するとすぐに問題として表面化してきました。 Workflow の実行履歴を際限なく取得してしまうため Web UI をホストしているコンポーネントが OOM になってしまうものでした。
Argo Workflows を安定した基盤として利用するためには即座にこの事象を解決する必要がありました。OSS であるということで、fix: Add limit to number of Workflows in CronWorkflow history の修正を提案し、無事受け入れてもらうことで解決となりました(ただし緊急度が高かったため取得件数を設定するだけにしています)。
また、この Pull Request をきっかけに Argo Workflows へのコントリビュートがしやすくなり、今後の改修の幅を広げることができたと思います。
Controller のメトリクスが消失する
原因不明ですが、事象として Datadog に送信しているメトリクスが消失することがあります。 これには 2つの事象があり、以下のようなものでした。
- ごくまれに Datadog に連携される前に Controller の再起動が行われ、メトリクスが消失してしまうことがある
- 一部のタグが正しく連携されず Datadog のフィルタ条件にマッチせず消失してるように見えることがある
タグが消失してしまう件については原因不明なので Controller を定期的に再起動することで事象を最低限に抑えています。 これらの影響で Datadog に成否のメトリクスを送信することを Workflow のデフォルト設定とすることが避けられませんでした。
Pod の作成時に OCI runtime create failed が発生する
Argo Workflows では失敗のステータスとして Error、Failed があります。
簡単に説明するとジョブのプログラムで問題がある場合は Failed で、それ以外は Error となります。
OCI runtime create failed はまれに Pod 作成時にコンテナが作成されず失敗する現象になります。
containerd で問題があるようですが詳しい原因まではわかっていません。
そのため TRANSIENT_ERROR_PATTERN に OCI runtime create failed を追加しリトライするようにして回避しています。
Workflow の終了時に pod deleted が発生する
私たちは Karpenter*3 を利用しており、もちろん Argo Workflows でも利用しています。
Argo Workflows は Workflow の実行時に Pod の終了ステータスから成功や失敗を判定しています。
もし Argo Workflows が Pod の終了ステータスを取得する前に Pod が消えた場合、成功や失敗を正しく判定できないので pod deleted というエラーが発生します。
私たちの環境では Pod が終了した瞬間にノードが消える場合があったため、このエラーが発生していました。
しばらく悩んでいましたが @44smkn さん、@int128 さんのご助力により、Karpenter NodePool の設定を以下のように Pod の終了から一定時間後にノードが消えるようにすることで、このエラーは改善しました。
apiVersion: karpenter.sh/v1 kind: NodePool metadata: name: nodepool spec: disruption: - expireAfter: Never + consolidationPolicy: WhenEmptyOrUnderutilized + consolidateAfter: 3m
argo-server が暴走する
Argo Workflows では workflow-controller と argo-server の 2つのコンポーネントが存在します。 argo-server は Web UI や API サーバのホストなどを担当していますが、あるタイミングで argo-server が OOM になり再起動を繰り返すようになりました。
この現象を観測した当初は原因はおろか再現方法まで謎だったため公式に報告できず困っていましたが、何度か観測を繰り返すうちに原因らしきものが掴めてきました。 結論から述べると Web UI のバグの可能性がありそうです。 workflow-controller のログに特定のユーザの操作が大量に残っており、意図した操作でないことを確認しブラウザを閉じていただいて収束したため、その可能性が高いと感じています。
まとめ
Argo Workflows を導入したことでジョブの安定性は向上し、Jenkins で課題だった点は解決しました。 ですが、以下のような別の課題が表面化されてしまいました。
- CSV ファイルを入力値にできない
- Kubernetes の情報が前面に出過ぎていている
- Workflow が検索しにくい
- 定期実行される Workflow を手動実行するときにパラメータを指定できない
私たちの組織では開発者以外にも利用者がいることもあり UI 面での改善要望が多くなっています。 これらは Argo Workflows へのコントリビュートも含めて解決していく予定です。
最後に
開発環境や本番環境など環境ごとに Jenkins サーバが存在しているため重複も多いですが 合計 1306 件あるジョブのほとんどで移行を完了することができました。 まだ完了していませんが今年中には残っている 48 件のジョブも全て移行し Jenkins を完全に停止していく予定です。 (執筆時点のステータスなので公開時には全て終わってる気がします)
ここまで移行が順調に進んだのは関係者全員がとても協力的だったことが大きかったです。 改めて関係者の皆さんに心より感謝の意を表します。