こんにちは。SRE の @int128 です。
Quipper では GitHub Actions Self-hosted Runner を一部のジョブで導入しています。本稿ではその目的と具体例を紹介します。
背景と解決したい課題
Quipper では以下の CI サービスを用途に合わせて利用しています。
- CircleCI(テストやデプロイなど)
- GitHub Actions(テストやデプロイなど)
- AWS CodeBuild(主に Terraform など AWS リソースにアクセスする場合)
- Google Cloud Build(主に Google Cloud のリソースにアクセスする場合)
- Jenkins(定期実行や手動実行に特化したジョブ)
このうち GitHub Actions は以下の点が優れていると感じています。
- monorepo 構成の場合にマイクロサービスごとに独立して Workflow を定義できる
- 公開 Action のエコシステムが発達している
- Workflow の定期実行やパラメータ付き手動実行にも対応している
一方で、クラウドに統合されている CI サービスと比較すると、GitHub Actions には以下の課題があります。
- Organization あたりのジョブの同時実行数が制限されている(正確な情報はドキュメントを参照してください)
- 実行環境からクラウドリソースにアクセスするにはクレデンシャル(例えば AWS では IAM access key)を渡す必要があるが、漏洩リスクやローテーション管理負荷を考えると避けたい
- 実行環境の時間単価が若干高めに設定されている
GitHub Actions には Self-hosted Runner という仕組みがあり、自分で用意した環境でジョブを実行することも可能です。 Self-hosted Runner を利用するとこれらの課題を解決できるのではないかと考えました。
Self-hosted Runner の実現方式
Self-hosted Runner の導入方法はドキュメントで丁寧に説明されており、誰でも簡単に使い始められます。 一方で、チーム開発では CI の安定性がとても重要なので、安定運用のためにいろいろと考える必要があります。
実行環境の配置と管理
まずは Self-hosted Runner をどんな環境で実行するかを考えます。Quipper のサービスの大部分は AWS で運用しているため、以下の選択肢があります。
- EC2 インスタンスで Self-hosted Runner を運用する
- Kubernetes クラスタで Self-hosted Runner を運用する
また、Self-hosted Runner を実行するインスタンスやコンテナを管理する方法も考える必要があります。 GitHub のドキュメントでは OS に手作業で Self-hosted Runner をインストールする方法が説明されていますが、この方法ではバージョンアップや台数追加などの日常運用に耐えられないと考えられます。
そこで Self-hosted Runner を宣言的に管理できる OSS を調査し、最終的に以下の選択肢に絞り込みました。
- https://github.com/philips-labs/terraform-aws-github-runner
- https://github.com/summerwind/actions-runner-controller
(1) は Self-hosted Runner の EC2 インスタンスを管理してくれる Terraform Module です。 Terraform で Runner を定義すると、TypeScript で書かれた Lambda が Runner を管理してくれるのが特徴的です。
(2) は Kubernetes クラスタ上で Self-hosted Runner の Pod を管理してくれる Custom Controller です。 カスタムリソースで Runner を定義すると、Go で書かれた Controller が Runner を管理してくれるのが特徴的です。
Quipper にはとても快適な Terraform の CI/CD の仕組みがあります。 一方で、Kubernetes クラスタのシステムコンポーネントは Argo CD で構成管理を行っています。 将来的に多くの Runner を管理する必要が生じたとしても、どちらの方式でも管理していけると考えました。
ロギングやモニタリングについては (1) (2) ともに十分にこなれています。 Quipper のサービスの大部分は Kubernetes で運用しているため、何か問題が起きた時のトラブルシューティングでは (2) の方が我々と親和性が高いと言えるかもしれません。
最終的には以下の点で (2) を採用しました。
- Quipper の技術顧問である @mumoshu さんが活発に開発に参加している
- カスタムリソースと Controller のオーナーシップが明確になっている。Developer が自分自身で必要なカスタムリソースを管理し、SRE が Controller を管理する世界を目指せる
以下、(2) を actions-runner-controller と表記します。
Autoscaling
Quipper では多くのテストを並列実行しており、瞬間的に多くの Runner が必要になります。 具体的には、最も多い場合で 60〜70 件のジョブが同時に実行されることがあります。 一方で、夜間はほとんどの人が寝ているのでピークタイムに合わせて Runner を用意するとコストが無駄になります。 そのため、Runner の Autoscaling は必須と考えました。
actions-runner-controller では以下の Autoscaling 方式に対応しています。
- 実行中のジョブ数から必要な Runner 数を算出する (TotalNumberOfQueuedAndInProgressWorkflowRuns)
- Busy Runner の割合を元に Runner の追加や削除を行う (PercentageRunnersBusy)
- GitHub からの Webhook を契機に Runner を追加する (ScaleUpTrigger)
検証を始めた2021年1月時点では (1) (2) のみが利用可能でした。 テストを並列実行したところ以下の課題が見つかりました。
- 定期的に GitHub API でメトリクスを取得するため、取得間隔を短くすると Rate Limit を使い切ってしまう
- Runner 数が増加すると、Runner の登録や更新で Rate Limit を使い切ってしまう
- 方式 (2) では Runner 数が十分に増加するまで時間がかかりすぎるため実用的でない。前項の Rate Limit の問題も発生してしまう
- Rate Limit や Autoscaling に関するメトリクスがないため、問題の切り分けが難しい
これらの課題を @mumoshu さんに相談したところ、方式 (3) を圧倒的速度で実現していただけました。 Webhook Autoscaling の仕組みを下図に示します*1。
GitHub でジョブが実行されると、actions-runner-controller が Webhook を受信して必要な Runner を追加するようになっています。 実際には後述するカスタムリソースを組み合わせた非同期処理で Autoscaling を実現しているため、問題の切り分けや対処はなかなかの難易度でした。 @mumoshu さんと協力しながらバグの修正や安定性の改善を進めました。
Webhook Autoscaling の仕組みを実際に運用してみると以下の課題がありました。
- 現状の GitHub API 仕様では GitHub-hosted runner と Self-hosted runner を区別する方法がないため、両者が混在する場合に Runner が無駄に増えてしまう
- Runner が急激に増加すると不安定になる
課題 (1) については、Webhook を受信した後に Runner を短時間だけ増やすことで、コストが大きく増えないようにしています*2。 また、定期的に実行されるジョブをスケールアウトの対象から除外することで、夜間は確実にノード数が減るように対策しています。
課題 (2) については、Runner に対する CPU やメモリの割り当てを見直す、ECR Public Gallary にあるイメージを利用する、といった施策を試しています。
Monitoring
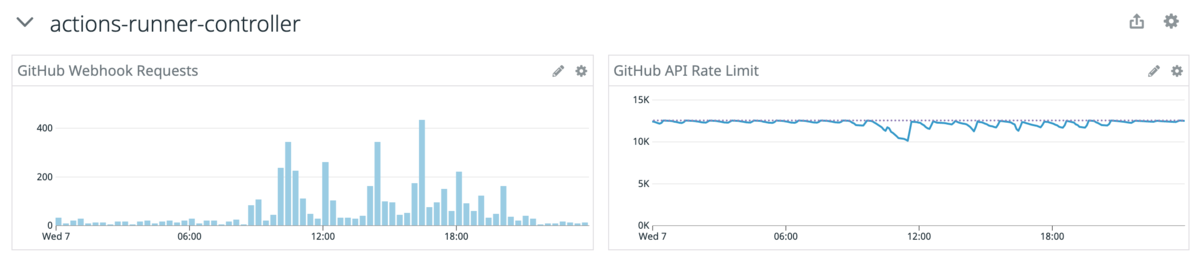
前項で述べたように actions-runner-controller では Rate Limit や Autoscaling に関するメトリクスを取得できなかったため、機能追加の Pull Request を送りました。 Datadog でメトリクスを確認できるようになったため、トラブルシュートで役に立っています。
下図のように、日中帯はジョブの実行数が多く、夜間はほとんどないことが分かります。

また、GitHub API Rate Limit はまだ余裕があるので、これから規模が大きくなっても当面は大丈夫そうです。
Self-hosted Runner の使い方と実際の運用
GitHub Actions のジョブが以下に該当する場合は Self-hosted Runner を推奨しています。
- 実行時間が長い
- 並列数が大きい
- AWS リソースにアクセスする(IAM Roles for Service Accounts を利用)
以下の理由でリポジトリ単位に Runner を管理しています。今のところ Organization 単位の Runner は使っていません。
- Runner のオーナーシップが明確になる(共通化で誰もメンテナンスしなくなるのを防ぐ)
- Quipper では monorepo を採用しているため、Runner を設定する必要のあるリポジトリが少ない
- リポジトリごとに必要な CPU やメモリのリソースが異なる
- リポジトリごとに必要最小限の IAM 権限を割り当てたい
Runner の構成管理
actions-runner-controller では以下のカスタムリソースで構成を管理します。
- Runner Deployment(Runner に関する設定)
- Horizontal Runner Autoscaler(Autoscaling に関する設定)
Runner Deployment リソースの例を以下に示します。Runner を関連づけるリポジトリや Runner に割り当てるリソースを指定します。
apiVersion: actions.summerwind.dev/v1alpha1 kind: RunnerDeployment metadata: name: REPOSITORY_NAME spec: template: spec: repository: quipper/REPOSITORY_NAME labels: - REPOSITORY_NAME-repository-runner resources: limits: memory: 1000Mi requests: cpu: 500m memory: 1000Mi
Horizontal Runner Autoscaler リソースの例を以下に示します。ここでは GitHub から check_run イベントを受信すると Runner を1台増加させています。
apiVersion: actions.summerwind.dev/v1alpha1 kind: HorizontalRunnerAutoscaler metadata: name: REPOSITORY_NAME spec: minReplicas: 1 maxReplicas: 30 scaleTargetRef: name: REPOSITORY_NAME scaleUpTriggers: - githubEvent: checkRun: types: - created status: queued duration: 45s amount: 1
actions-runner-controller はこれらのカスタムリソースから必要な Pod を作成し、GitHub Actions のジョブを実行する環境を整えます。
GitOps による構成管理
Runner のカスタムリソースは Git リポジトリで管理しています。 具体的には以下のようなディレクトリ構成で管理しています。
.
└── system-components
└── overlays
└── CLUSTER_NAME
└── github-actions-repository-runners
├── horizontalrunnerautoscaler
| └── REPOSITORY_NAME.yaml
├── runnerdeployment
| └── REPOSITORY_NAME.yaml
└── serviceaccount
└── REPOSITORY_NAME.yaml
Runner の追加や変更は以下の手順で行っています。
- マニフェストを変更する(例えば CPU やメモリの割り当てを変更)
- Pull Request のレビューリクエストを出す
- Pull Request をマージする
- Argo CD によってクラスタに変更が適用される
Self-hosted Runner の具体例
現在、以下の用途で Self-hosted Runner を導入しています。
- Kubernetes System Components を管理するリポジトリ(SRE が日常的に使うリポジトリに先行導入することで問題に早く気づけるようにしています)
- 並列数の大きい RSpec テスト
- React Storybook やドキュメントなどを S3 Bucket に配置するジョブ
- EC2 などを定期的にメンテナンスするジョブ
- BuildKit キャッシュを利用したビルドの検証
GitHub-hosted から Self-hosted への移行にあたっては、Developer と SRE が協力しながら段階的に移行を進めています。 特に RSpec のテストについては Web Developer の @mtsmfm さんから多くのフィードバックをもらえたので、問題の発見と対処を確実に進めることができました。
Self-hosted Runner は EKS クラスタで実行しているため、EKS クラスタが停止している時は利用できません。 このため、AWS リソースを管理する Terraform などは Self-hosted Runner ではなく AWS CodeBuild のようなマネージドサービスが適しています。 このように適材適所で CI サービスを利用することが重要と考えています。
まとめ
GitHub Actions (GitHub-hosted Runner) には以下の課題があることを冒頭で説明しました。
- Organization あたりのジョブの同時実行数が制限されている
- 実行環境からクラウドリソースにアクセスするにはクレデンシャルを渡す必要があるが、漏洩リスクやローテーション管理負荷を考えると避けたい
- 実行環境の時間単価が若干高めに設定されている
Self-hosted Runner の導入により、以下のように課題を解決できたと考えています。
- 同時実行数の制限がなくなった
- IAM Roles for Service Accounts を利用することで、クレデンシャルを使わずに権限を割り当てられる(セキュリティの改善)
- EC2 Spot Instances を利用することで、インスタンスの時間単価を抑えられる(コストの改善)
Self-hosted Runner の導入はまだ始まったばかりで、急激にジョブ数が増加した場合の安定性や実際に導入する際の理解の難しさはまだまだ改善が必要です。 また、ジョブの待ち時間やコストなどの改善を定量的に分析していく必要があります。 ぜひ Quipper に入社して一緒にチャレンジしてみませんか?
Quipper では世界の果てまで学びを届けたい仲間を募集しています。