こんにちは。スタディサプリ小中高 / Quipper SREの@kyontanです。
この記事は Recruit Engineers Advent Calendar 2022 の1日目の記事です。
開発チームが事実に基づいて(= fact-basedな)意思決定をできるようにするための一助として、SREチームではSLO (Service Level Objective)が設定されていることをサービス公開時の要件としています。
スタディサプリ小中高におけるSLOの運用については、以前弊チームの@chaspyが SRE NEXT 2020 で「SLO Review」というタイトルで登壇しました #srenext という記事を書いているので、こちらもご参照ください。
本記事では、これまでしきい値によるアラートを設定していたSLOについて、Burn Rateによるモニタリングを試してみたので、ざっくりご紹介できればと思います。
背景
スタディサプリ小中高では、大半のマイクロサービスが以下の2つのSLI(Service Level Indicator)を定義しています。
- HTTPエラーレート (HTTP 5xx statusの割合)
- HTTPレスポンスタイム
SLOの設定値や、エラーバジェットが枯渇した場合の対応方針などは、それぞれのマイクロサービスの開発チームに一任されています。 全チームの対応方針を把握しているわけではないので主観にはなりますが、週次などでチームのダッシュボードを見て振り返る取り組みをしているチームが多いと感じています。
Burn Rate Monitoring について
Burn Rate Monitoringとは、エラーバジェットの消費速度に対するモニタリングの手法であり、SRE Workbook の Alerting on SLOsの"4: Alert on Burn Rate"というセクションで紹介されています。 これに対し、典型的なError Budget Monitoring(しきい値によるモニタリング)の場合はエラーバジェットを消費しきったか(あるいは一定のエラーバジェット残量を下回ったかどうか)で判定します。
Burn Rate = 1 というのは、SLOの定められた期間にエラーバジェットをちょうど消化しきる状態を指しており、Burn Rate = 2 のときはその2倍の速度でエラーが起きていることになります。逆に、Burn Rate が常に1以下であればエラーバジェットを消化しきることはありません。
Burn Rate Monitoringのメリットとして、消費速度に対するモニタリングでは特定のリリースによる影響などを素早く検知できるメリットがあります。 たとえば、あるリリースを起点としてエラーレートがやや上昇し、エラーバジェットが定められたSLO window(一般的には7日や30日など)にギリギリ使い切るようなシチュエーションを想定してみます。
Error Budget Monitoringの場合はエラーバジェットが枯渇した段階、つまりリリースから数日後にアラートで気がつくことになり、原因の究明が困難であったり、修正に時間を要することもあるかもしれません。
一方で、Burn Rate Monitoringの場合は、リリースを起点としてBurn Rateが1以上の値を取ることになります。 どの程度のBurn Rateでアラートを受け取るかは状況にもよりますが、仮にBurn Rateが1以上のときにアラートを受け取っている場合であれば、リリースしてすぐにアラートに気付くことができるため、原因究明や修正がError Budget Monitoringと比較するとスムーズに行えた可能性が高いです。
Burn Rate Monitoringを導入した結果
このような良いことずくめのBurn Rate Monitoringですが、弊プロダクトで利用しているDatadogにおいてもサポートされており、Monitorの設定方法の1つとして提供されています。
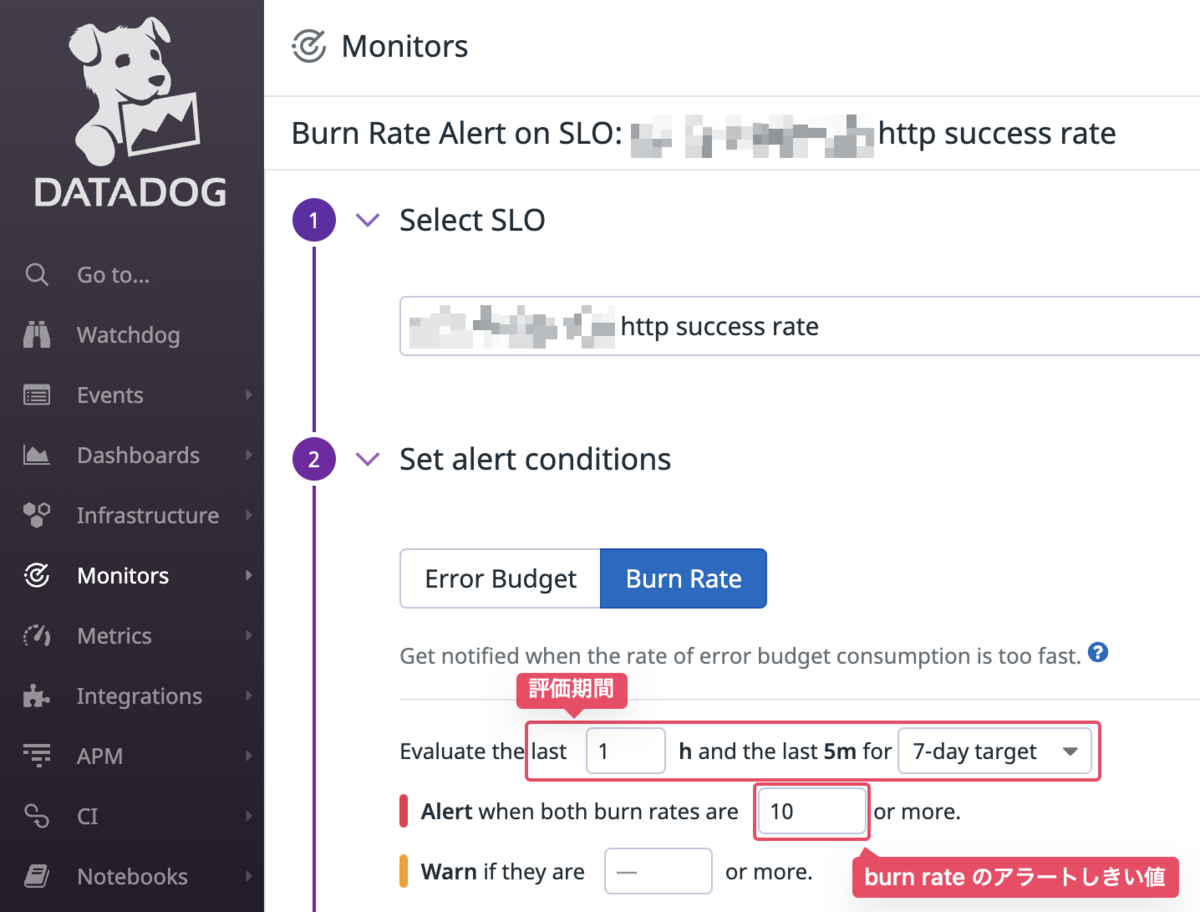
試しにあるチームでBurn Rate Monitoringを導入してみましたが、最初はBurn Rateがどの程度を超えたらアラートとすべきかの設定が難しいと感じました。
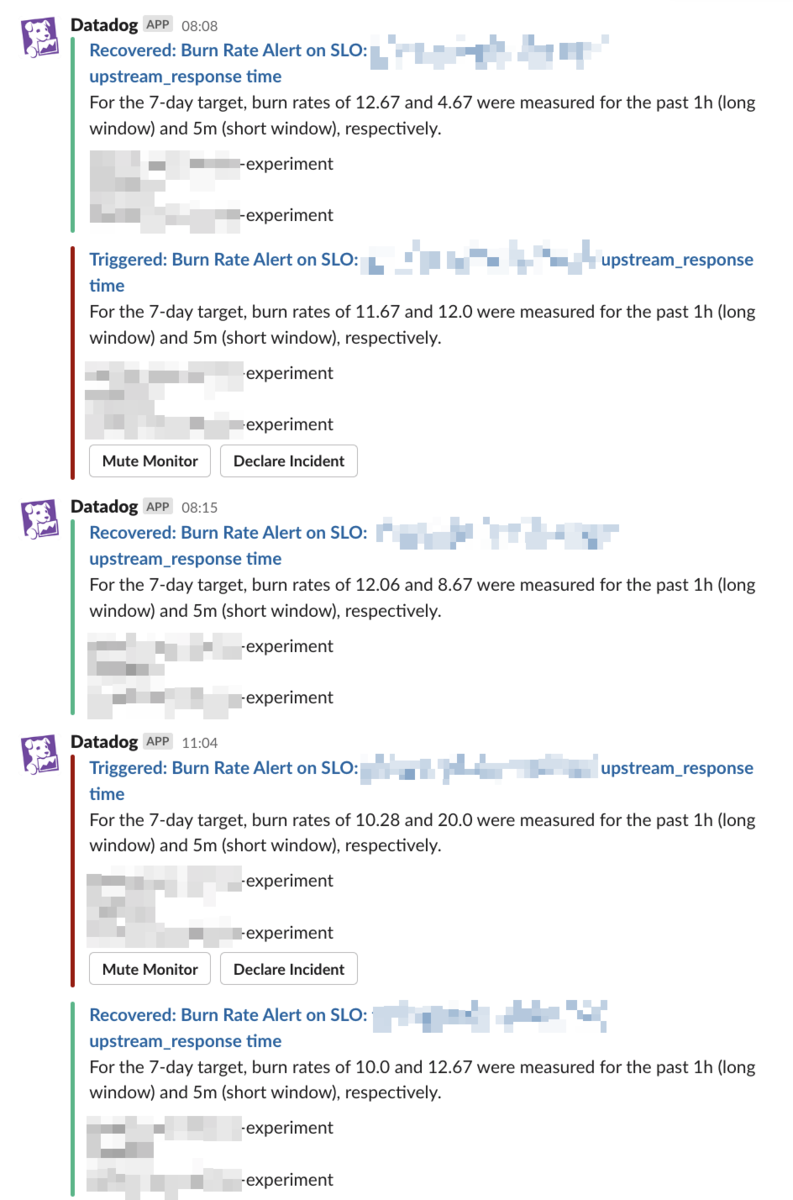
これについては、multi-windowという手法を導入することで改善できます。 具体的には異なるSLO windowでのBurn Rateを監視するようにし、長いSLO windowでのBurn Rateが一定以上になったらアラートを発報、短いSLO windowでのBurn Rateが一定以下になった時点で回復とすることで、アラートのflappingを防ぎつつ事象の解決時には早期にアラートを解消させることができます。 これはまさにAlerting on SLOsの"6: Multiwindow, Multi-Burn-Rate Alerts"のセクションで紹介されている内容であり、図も使って分かりやすく説明されているので、ぜひ原文を参照頂ければと思います。
参考までに、Datadogではデフォルトでこれらを考慮した設定が可能になっているため、複雑な評価式などを書かずとも、window等のチューニングで適切な設定ができるようになっていました。
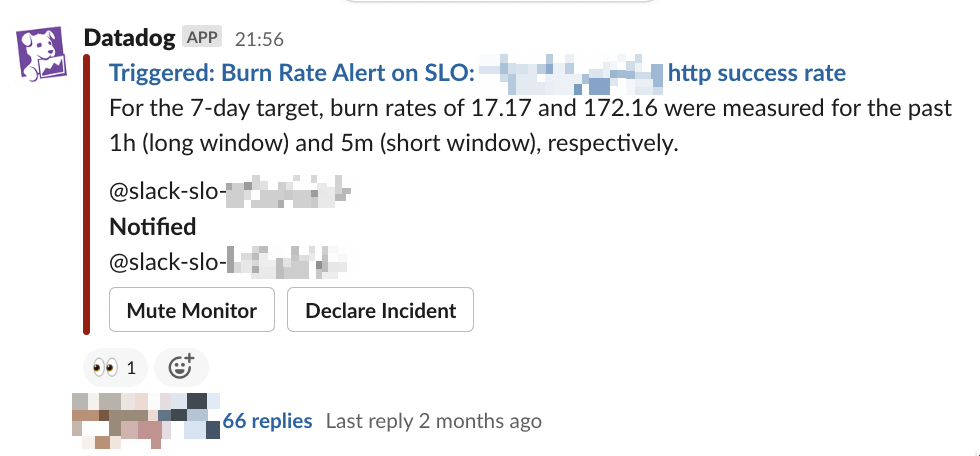
今後は、幅広くBurn Rate Monitoringを導入し、これまでのError Budget Monitoringとあわせ広く活用していければ良いなと考えています。
おわりに
本記事では、サービスが期待した動作をしていないことをより早期に検知するための仕組みとして、SLO Burn Rate Monitoringについてご紹介しました。
スタディサプリでは、引き続きサービスの信頼性を高め、開発者がより高速にサービスを改善していけるためのプラットフォームを作っていく仲間を募集しています。
https://brand.studysapuri.jp/career/
また、Recruit Engineers Advent Calendar 2022ではリクルートのエンジニア陣が記事を投稿していく予定です。もしリクルートにおけるエンジニアリングに興味があれば、ぜひ他の記事もあわせてご参照ください。