こんにちは。SRE の @int128 です。
先日の「負荷試験、Gatling を使ってやってみた」で紹介したように、スタディサプリではユーザ体験の改善や本番障害の予防を目的に負荷試験を行っています。 本稿では、SRE と Product Team がどのようにして一緒に負荷試験に取り組んでいるか、考え方や仕組みを紹介します。
背景
SRE では新しいマイクロサービスの開発や機能追加の契機で Production Readiness Check を行っています。 具体的には、Product Team がテンプレートにしたがって Production Readiness Checklist を記入して、SRE と一緒にレビューを行っています。 その際に、トラフィックが多い、あるいは、レイテンシが厳しい、といったリスクがある場合に負荷試験を行うことにしています。
負荷試験は以下の流れで実施しています。
非機能要件やアーキテクチャを整理する段階から負荷試験を計画することが望ましいため、SRE では早めに Product Team に声を掛けるようにしています。 リリースの直前に負荷試験を行うと、パフォーマンスチューニングなどの問題解決の時間が確保できなくなってしまいます。
Product Team が負荷試験で必要な情報をまとめやすいように、下記のような Issue Template を用意しています。
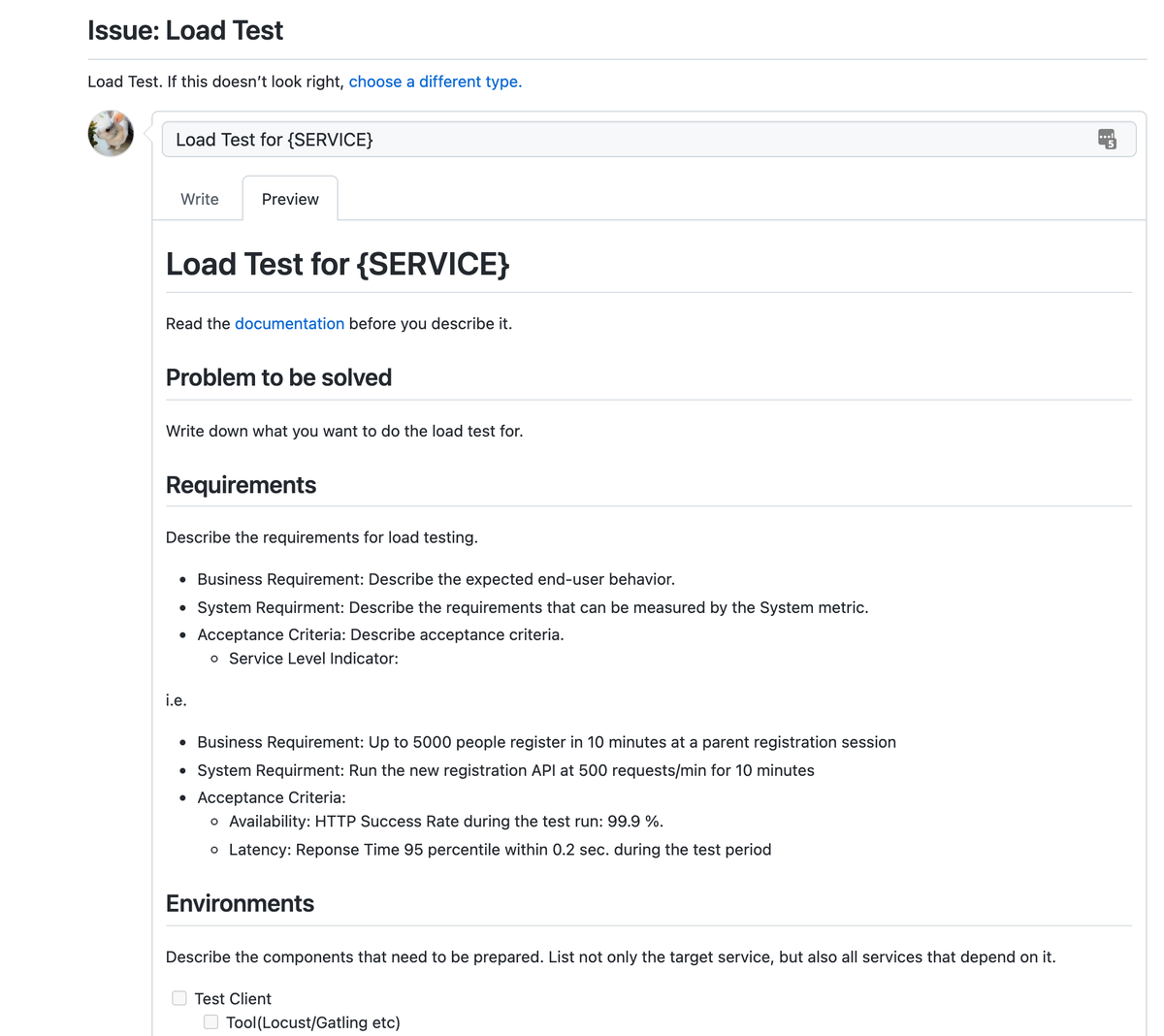
解決したい課題と解決策
筆者が過去に取り組んだ負荷試験では、以下のような課題を経験してきました。
- 特定の人しか試験環境を準備できないので待ち時間が発生する
- 試験環境が固定数しかないので待ち時間が発生する
- テストデータの準備に手間や時間がかかる
- 試験結果の収集に手間や時間がかかる
スタディサプリでは Product Team が自己完結で開発や運用を進められる世界を目指しています。 そのためには、クラウドや自己完結チームを前提にして負荷試験のプロセスや技術スタックを考えていく必要があります。
負荷試験環境の構成
スタディサプリでは AWS の Kubernetes クラスタでサービスを開発および運用しています。 また、Kubernetes クラスタ上で GitHub Actions Self-hosted Runner を導入しています。 これらの仕組みを用いて前述の課題を解決することを考えました。
負荷試験では以下の技術スタックを採用しています。
- 負荷生成
- シナリオ (Gatling)
- 実行環境 (GitHub Actions self-hosted runner on Kubernetes)
- 試験対象
- アプリケーション (Ruby on Rails, Go, ...)
- データベースやキャッシュなど (RDS Aurora, MongoDB, ElastiCache, ...)
- 実行環境 (Kubernetes)
負荷生成環境の構成を下図に示します。
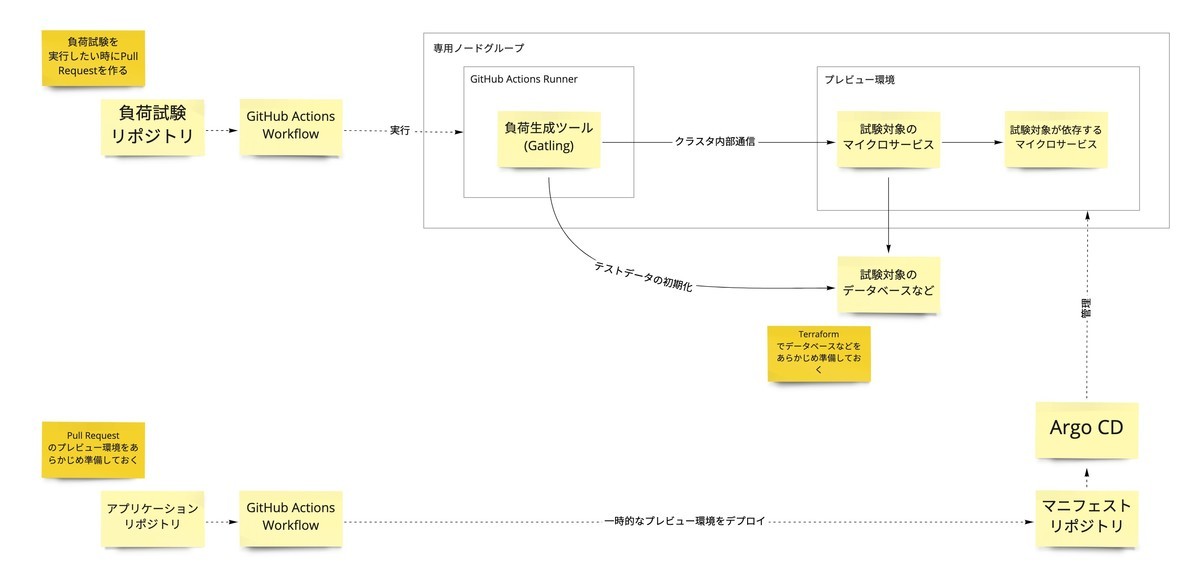
アプリケーションリポジトリに Pull Request を作成すると一時的なプレビュー環境がデプロイされる仕組みがあります。 負荷試験でもプレビュー環境を利用して試験対象のマイクロサービス群をデプロイします。
負荷試験を実行するには、負荷試験シナリオのリポジトリで Pull Request を作成します。 この契機で GitHub Actions の self-hosted runner で Gatling が実行されるようになっています。 詳しい仕組みは後述します。
安定した負荷を掛けるためには、負荷生成と試験対象をネットワーク的に近い場所に配置する必要があります。 例えば、自宅からインターネット経由でクラウド上のアプリケーションに負荷を掛けても、レイテンシの分散が大きいため安定した負荷が掛かりません。 スタディサプリへのトラフィックは CDN, Reverse Proxy, Kubernetes などで処理されますが、以下の理由で Kubernetes クラスタの内部通信で負荷を掛けています。
- 全体の処理時間のうちアプリケーションの処理時間が支配的なので、ほとんどのユースケースでは Kubernetes 外にある構成要素を無視できる
- 構成をなるべくシンプルにすることで、準備や調査を容易にしたい
実行環境の準備
スタディサプリは複数のマイクロサービスで構成されるため、複数のチームが同時に負荷試験を行う場合もあります。 そのため、チーム単位に独立した負荷試験環境が必要になります。 せっかくクラウドを採用しているのだから、必要な時に必要な量のリソースを準備できるのが理想ですね。
負荷試験では以下の構想要素が必要になりますが、Product Team が自分たちで準備できるようにしています。
- Gatling や アプリケーションを実行するための Kubernetes ノードグループ (Terraform)
- Gatling を実行するための GitHub Actions Runner (Kubernetes manifests)
- データベースなどの AWS リソース (Terraform)
- 本番に近いデータが必要な場合、個人情報をマスク済みのスナップショットを利用できます *1
- 試験対象のアプリケーション
- アプリケーションリポジトリに Pull Request を作成するとプレビュー環境がデプロイされます
- 専用のノードグループに配置されるように
nodeAffinityを変更します - 専用のデータベースを参照するように変更します
- 必要に応じて HPA を設定します
基本的には Terraform や Kubernetes manifests のリポジトリで Pull Request をマージすれば変更が適用されるようになっています。 コード管理できないリソースが一部残っているため、まれに SRE の手作業が必要になります。
現実には SRE がサポートしながら準備を進めることが多いですが、スケールアップなどの変更は Product Team で進めてもらうようにしています。
快適で安定したサービスを提供するには、本番環境へのリリース後もパフォーマンスの問題に継続的に対応していく必要があります。 そのため、負荷試験でも本番環境と同じツールを使うことが望ましいと考えています。 スタディサプリでは Datadog, New Relic, Sentry などを採用しており、負荷試験の調査や分析でも同じツールを利用しています。
シナリオの準備と実行
負荷試験では要件に合わせてシナリオを作成していきますが、実際に動かしてみないと分からない問題も多く出てきます。 このような不確実性の高いタスクでは試行錯誤を高速に繰り返しやすい環境が重要になってきます。
シナリオ(Gatling では simulation と呼んでいます)はローカルの IntelliJ IDEA や Visual Studio Code などで開発しています。 シナリオの実行には試験対象のアプリケーションやデータベースが必要ですが、Kubernetes クラスタにポートフォワードすることでローカルでも実行は可能です。 ただし、前述のように、高い負荷を掛けるには Kubernetes クラスタの内部で Gatling を実行する必要があります。
試行錯誤を高速に繰り返すにはデプロイや実行を簡単にする必要があります。 そこで、リポジトリに Pull Request を作成すると Kubernetes クラスタで Gatling が実行される仕組みを用意しています。 具体的には、以下の流れで負荷試験を実行します。
- Developer が Pull Request を作成する(もしくはコミットを更新する)
- GitHub Actions が Gatling をビルドする
- GitHub Actions が self-hosted runner で Gatling を実行する
- GitHub Actions が Gatling のレポートを S3 バケットに配置する
- Developer はブラウザから Gatling のレポートを確認する
すべての Pull Request で Gatling を実行するとチーム作業に支障をきたすため、ブランチ名がパターン loadtest/Gatlingのクラス名/任意の文字列 にマッチする場合のみ実行しています。
Gatling では Scala のシナリオを直接実行することも可能ですが、以下の理由によりビルド済みの Gatling を実行する仕組みにしています。
具体的には、gatling-sbt plugin と sbt-native-packager plugin を組み合わせることで、Gatling とシナリオを1つの JAR にまとめています。
// plugins/plugins.sbt addSbtPlugin("com.typesafe.sbt" % "sbt-native-packager" % "1.7.6") addSbtPlugin("io.gatling" % "gatling-sbt" % "3.2.2")
// build.sbt val gatlingVersion = "3.5.1" libraryDependencies += "io.gatling.highcharts" % "gatling-charts-highcharts" % gatlingVersion libraryDependencies += "io.gatling" % "gatling-test-framework" % gatlingVersion mainClass in Compile := Some("io.gatling.app.Gatling") scalaSource in Compile := baseDirectory.value / "src/test/scala" resourceDirectory in Compile := baseDirectory.value / "src/test/resources"
Gatling の実行が完了すると、下図のように Pull Request のコメントでレポートが通知されます。
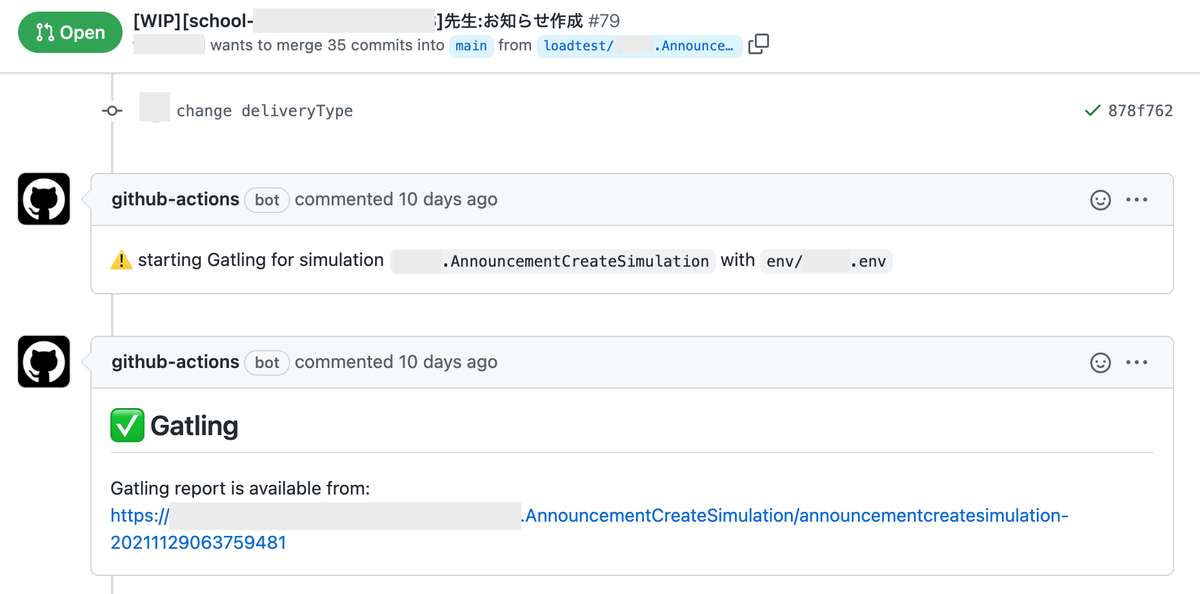
GitHub Actions は様々なトリガーをサポートしています。 例えば Pull Request に何らかのコメントを書いたら Gatling が実行されるといったワークフローを組むことも可能です。
テストデータの準備
試行錯誤を繰り返すにあたり、テストデータの準備はボトルネックになることが多いと思います。 負荷試験ではテストデータの性質に応じて以下の方法を使い分けています。
- シナリオの実行時に動的にテストデータを生成する
- ジョブでテストデータを一括生成する
- 本番環境から個人情報をマスク済みのスナップショットを利用する
シナリオの実行時に動的にテストデータを生成する方法については @chata さんの記事で詳しく紹介されています。 テストデータを生成するロジックも Pull Request で確認できるため、チームで作業を進めるのに適していると思います。
以下のようにデータベースアクセスに必要な依存関係を追加すると、シナリオからデータベースにアクセスできるようになります。
libraryDependencies += "org.mongodb.scala" %% "mongo-scala-driver" % "4.4.0" libraryDependencies += "org.postgresql" % "postgresql" % "42.3.1"
本番環境から個人情報をマスク済みのスナップショットを利用する方法については、これまで Jenkins のジョブやスクリプトを複製するという複雑な手順が必要でしたが、Terraform で完結できるように改善を進めています。
効果と今後の課題
これまで述べた仕組みにより、負荷試験の実行とチューニングのサイクルを素早く回すことが可能になりました。 以下のような効果があったと考えています。
- 負荷試験に必要な環境をすぐに準備できる
- チーム単位に独立した試験環境が使えるので待たずに済む
- 誰でも Gatling のレポートにアクセスできるので、Slack などで議論しやすい
- ボトルネックの分析や改善などの本質的な作業に時間を割ける
結果的に、負荷試験の目的であるユーザ体験の向上や本番障害の予防に寄与できているのではないかと考えています。
現状は Production Readiness Check として負荷試験を実施していますが、将来的には日常の開発サイクルに組み込んで継続的に実行できないか検討しています。 そのためにはシナリオやテストデータをいかに継続的にメンテナンスしていくかが鍵になると考えています。
まとめ
本稿では Product Team が負荷試験を進めるためのサポートや、負荷試験とチューニングを高速に繰り返すための仕組みを紹介しました。
SRE では最高のプロダクトを支える最高のプラットフォームを実現するメンバーを募集しています。 ぜひカジュアル面談でお話ししてみませんか。