こんにちは。SREのkyontanです。Rubyが大好きなのでRubyの話をします。ちなみにリクルートはRubyKaigi 2024へGold Sponsorとして協賛しています! *1。ぜひ沖縄でお会いしましょう。
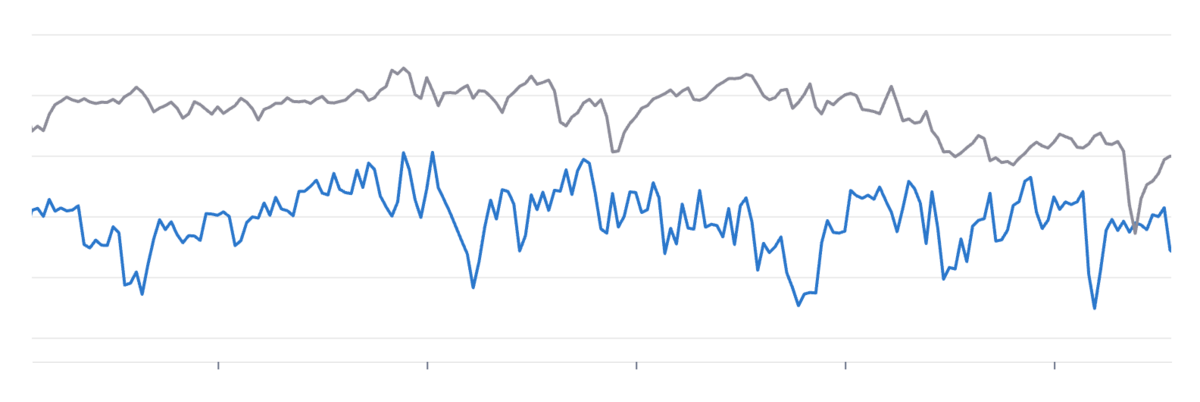 これはあるアプリケーションのメモリ消費量を示すグラフなのですが、まさかgemを入れ替えるだけでこんなに嬉しい変化が見られるとは思っていませんでした。今日はそんなgemの話をします。
これはあるアプリケーションのメモリ消費量を示すグラフなのですが、まさかgemを入れ替えるだけでこんなに嬉しい変化が見られるとは思っていませんでした。今日はそんなgemの話をします。
話は遡って2023年4月のある日、インターネットを眺めていたところ、ShopifyがpitchforkというOSSを公開したという情報が目に留まりました。 調べてみると、どうやら著名なRackサーバー実装の1つであるunicornの派生版であり、メモリ使用量の削減に特化しているらしいのです。
これはスタディサプリ小中高のあのリソースドカ食いマイクロサービス第一位である api *2 *3 に入れるしかない……!と思い立ち、2度のトライを経てついに先日、本番環境で安定運用に入りました。
本記事では、そんなpitchforkを紹介したのち、スタディサプリ小中高においてリリースするまでの道のり、導入後の効果をお届けします。
Rackサーバーとthread-safety
pitchforkは、reforkingという独特な概念を取り入れたRackサーバー実装です。 *4 Ruby on RailsやSinatraなど、Rubyの多くのWebフレームワークはRackインタフェースに則って実装されており、必要に応じて好きなサーバーの実装を選択することができます。
Ruby on Railsでは5.0からpumaがデフォルトのRackサーバーとして採用されており *5 、多くのユーザーはpumaを使い続けていることでしょう。
しかし、thread-safeでないコードが存在する場合には、multi-threadなRackサーバーを利用できないケースがあります。 スタディサプリ小中高では、ほぼ全てのRailsアプリケーションで利用しているmongomapper gem が thread-safe でないという課題があり、長年に渡りunicornを使い続けていました。
prefork と reforking
unicornは伝統的なpreforkモデルを採用しています。親プロセス(master process)は起動時にworkerプロセスをforkし、masterは受け取ったHTTPリクエストをworkerに処理させます。
さて、LinuxにおけるプロセスのforkはCoW (Copy-On-Write)と呼ばれ、fork直後のプロセスはメモリの大半を親プロセスと(物理的に)共有します。 この共有されている領域に対して親や子が書き込みを行うと、それらのデータはそのとき初めて元の領域とは異なる領域に書き込まれます。これらの処理はOSにより透過的に行われるため、各プロセスはあたかも最初から独自のメモリ領域を持っているかのように振る舞うことができ、OSはfork後に書き込みが行われるまでは同一のメモリ領域を親子のプロセスで共有することで実メモリの使用量を削減しています。
ここで、RubyやRailsのワークロードの特徴を観察してみると、非常に興味深い事実が判明します。 Railsでは、ActiveRecordを始めとして多くのコードやインスタンスの初期化はリクエストの処理が行われるまで遅延されます。また、YJITなどのJITの存在により、リクエストを処理していく度にメソッドの実装がメモリ上で最適化されていきます。 このようなワークロードでは、worker processのfork後に大量のメモリ書き込みが発生するため、unicornのようなpreforkモデルでは、CoWの恩恵をあまり受けられなくなってしまう(=メモリ使用量が増大する)という欠点がありました。
この課題に対し、pitchforkはreforkingという大胆なテクニックを導入することで解決しています。 これはざっくり説明すると「ある程度リクエストを処理したworkerを次世代のworkerの親にする」というものです。 実際にはこれを複数回繰り返すことが想定されており(設定で制御可能)、CoWの効率をより高める工夫がなされています。
詳しい説明はオリジナルの作者の1人であるbyroot氏による説明や、公式のドキュメントが非常に分かりやすいです。
pitchfork の導入
私は2023/4にpitchforkの存在を知った直後に、pitchforkの導入を試みました。しかし、当時はapiのコードベースに詳しくなく、大量のエラーと謎のスタックトレースに悩まされ一度導入を断念しています。*6
しかし、いつか導入できると信じ、2023/5に松本で行われたRubyKaigi 2023に参加した際にはAfter Partyでbyroot氏とも対面で会話し、多分そのワークロードだとうまく動くと思う、みたいな会話をした記憶がうっすらとあります。*7 *8
その後はしばらく本業 *9 が忙しく、あまり手を付けられずにいたのですが、2024/3になって改めて再挑戦してみようと思い立ち、取組みを開始しました。
大きな部分はunicornと大差ないのですが、pitchforkはそのreforkingという仕組みのため、callbackが大きく異なります。unicornにはないmold というプロセスが登場するため、ドキュメントに一通り目を通すのが良いでしょう。
スタディサプリ小中高の api でも、これまで unicorn の設定で fork 前後にデータベース等のコネクションをハンドリングしているコードがあったため、これらを注意深く修正しました。
小ネタですが、ドキュメントにはメモリ効率を最大化するため、 after_mold_fork で GCを数回実行するテクニックが紹介されていました。このあたりも拾っておくとよいでしょう。
他にも、api では OOM対策として、unicorn-worker-killerを利用していました。pitchforkではクラス名が変わるため、当初はこれをforkする予定でしたが、issueで訪ねたところafter_request_complete callbackで代替できるんじゃないか、ということで、確かにその通りだったので簡単に実装し直しました。以下が実際に動いているコードです。
またチューニングのため、YJITのメトリクスも簡易的にログへ出しています
after_request_complete do |server, worker, _env| if worker.requests_count % 1000 == 0 && defined?(RubyVM::YJIT) && RubyVM::YJIT.enabled? server.logger.info("[YJIT] nr:#{worker.nr}, gen:#{worker.generation}, requests:#{worker.requests_count}, runtime_stats: #{RubyVM::YJIT.runtime_stats}") end # 同時に多数の worker が kill されることを避けるため、しきい値に幅をもたせる threshold_requests = THRESHOLD_REQUEST_PER_WORKER_MIN + Random.rand(THRESHOLD_REQUEST_PER_WORKER_MAX - THRESHOLD_REQUEST_PER_WORKER_MIN) if worker.requests_count >= threshold_requests server.logger.info("restart worker due for threshold_requests") exit end threshold_memory_kb = THRESHOLD_KILL_WORKER_MEM_KB_MIN + Random.rand(THRESHOLD_KILL_WORKER_MEM_KB_MAX - THRESHOLD_KILL_WORKER_MEM_KB_MIN) meminfo = Pitchfork::MemInfo.new(worker.pid) if meminfo.pss >= threshold_memory_kb server.logger.info("restart worker due for memory") exit end end
ハマった点1: grpc gem の fork-safe対応
ドキュメントに記載がある通り、 grpc gem を利用している場合には特別な対応が必要です。
api もこの対応が必要であり、具体的には GRPC.prefork, GRPC.postfork_parent, GRPC.postfork_child といったメソッドを注意深く呼んでやる必要がありました。
上手くやる方法について悩んでissueを切ったらすぐに使えるcode snippet を提供頂けてとても助かりました。*10
ハマった点2: reforkingの頻度が多すぎてパフォーマンス悪化問題
api には、fork後に初期化が必要かつ、初期化コストがかなり大きい実装があり、これがreforkingによって顕在化しました。
pitchforkではどの程度リクエストを処理してからreforkするかをrefork_afterパラメータで設定するのですが、当初はこれが毎1000リクエストごとに行われるようになっていました。
refork_afterでは最後の要素がfalseでないときは、最後の要素に設定したリクエスト数を繰り返す度に無限にreforkが行われ、またrefork時には全workerを新たに再作成するために、重い初期化処理が大量に走りレスポンスタイムに大きく影響する、という事象が発生してしまいました。
この対策として、reforkを無限に繰り返してもメモリ使用量の削減にはあまり意味がないことをメトリクスから理解し、4世代、計6000リクエストほど処理した段階でreforkを止めるように設定したほか、重い初期化処理を after_worker_fork callback 内 (リクエスト外) で実行することでリクエストの処理時間に影響しないようにしました。
調査にあたっては当該APIの開発者チームの方々が素早くメトリクスの変化を察知し、原因究明、解決へと動いて頂き、とても助かりました。爆速でAPMを辿りながらパフォーマンス劣化を引き起こしているメソッドを特定する様は、さながらObservabilityの化身のようでした……
ハマった点3: 大量の segmentation fault
上記の問題を乗り越えつつ、開発環境でも安定して動作していることが確認できたため本番へリリースした数十分後、散発的に504エラーが大量発生する謎事象が発生しました。
慌てて異常な量のエラーログを見てみると、そこには大量のsegmentation faultの文字列とそれに連なるスタックトレースが……
使っているgemが悪いのだろうか……先は長そうだ……と思いつつpitchforkにissueを立ててみると、なんと40分で解決しました。Ruby 3.2.2までに存在するObjectSpace::WeakMapのバグのようでした。
Ruby 3.2.3にアップグレードしたところ無事解決し、以後は特に問題もなく安定して動作しています。
得られたもの
注意事項として、今回のpitchforkの導入と同時にYJITを有効化しており、またworker process数などのパラメータチューニングも並行して進めました。 そのため、純粋なpitchforkの有無に対する評価はほぼしていません。また、同一トラフィック下の測定ではありません。 評価環境は Linux (x86, 64-bit), Ruby 3.2.3 です。
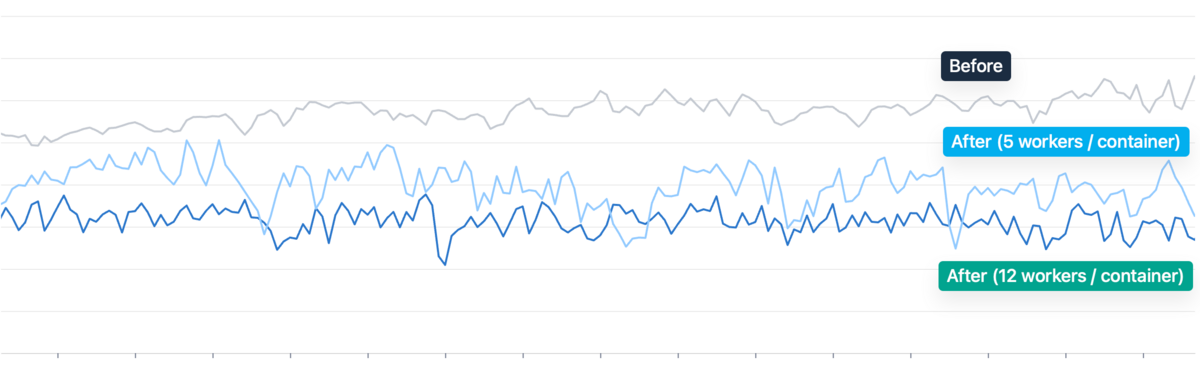
ワーカーあたりメモリ消費量
- unicorn, 5 workers / container: 100%
- pitchfork, 5 workers / container: 81.9%
- pitchfork, 12 workers / container: 73.3%
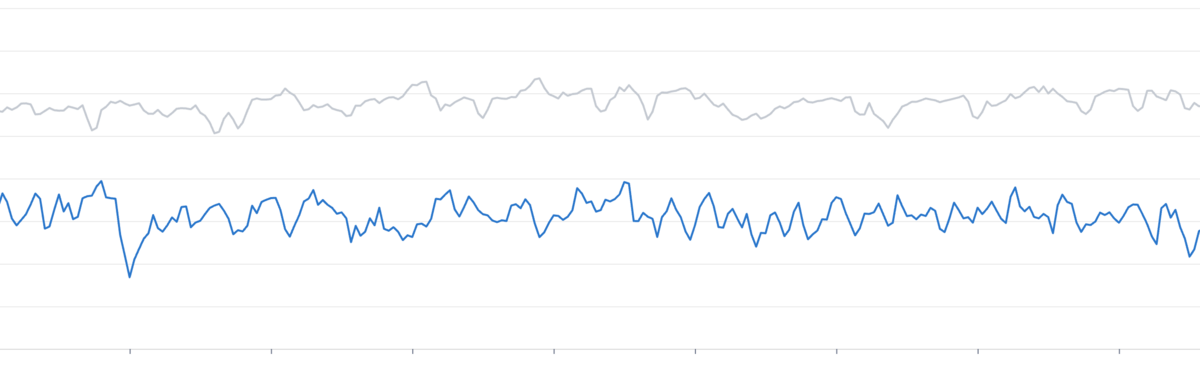
総メモリ使用量
- unicorn, 5 workers / container: 100%
- pitchfork, 12 workers / container: 40.9%
HPA (KubernetesのPod Autoscaler)の設定を変更したため、その影響を打ち消すように補正して計算した値 (かつ比較的差が付いていない時間帯を恣意的に選択した)なのですが、ここまで減るとは思っていませんでした。あくまで推測にはなりますが、YJITによりCPU使用率が下がった結果として必要なコンテナ数が減ったことが寄与しているように思います。
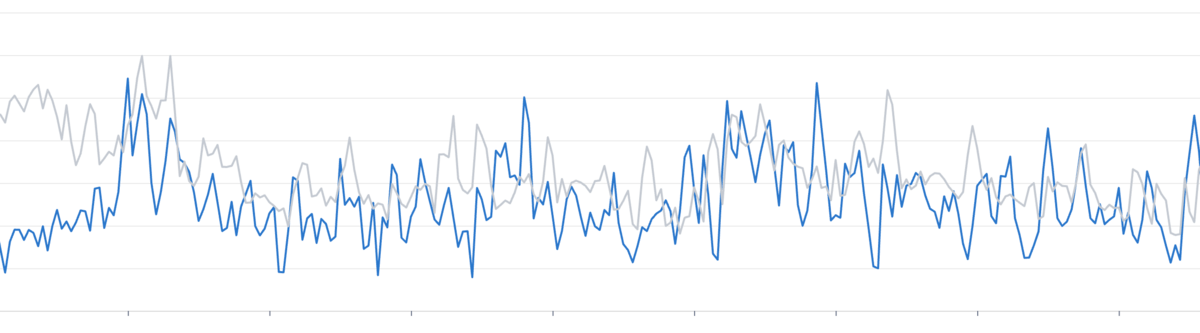
総CPUリソース
- unicorn, 5 workers / container: 100%
- pitchfork, 12 workers / container: 86.7%
これはYJITの効果による部分が如実に出たのではないでしょうか。 ちなみにレスポンスタイムが良くなったらもっと嬉しかったのですが、レスポンスタイムはほぼ変化が見られませんでした。とはいえ少ないリソースで同等のパフォーマンスを維持できることはとても素晴らしいです。
まとめ
本記事では、最近登場したRackサーバー実装であるpitchforkについて紹介し、スタディサプリ小中高を支える最大のRailsアプリケーションへ導入するまでの道のりと、導入により得られた成果について紹介しました。
日頃の私はSREとして開発体験を支えるプラットフォームの改善に取り組むことが多いのですが、久々に大好きなRubyでサービスの改善に貢献することができとても楽しかったです。 今回の取組みにあたりサポート頂いた同僚と、連日issueやXなどで導入にあたって多大なるサポートをしてくれたbyroot氏へ感謝の意を表すとともに、この取組みが読者の皆さまの参考になれば幸いです。
更新
- Rails における
config.eager_load = trueの場合には多くのクラスの初期化等は起動時に行われ、リクエスト処理時のオーバーヘッドにはならないため、記述を削除しました。 https://twitter.com/_byroot/status/1775063874045141198 - puma にも Fork-Worker Cluster Mode があり、refork という概念は pitchfork 唯一の概念ではないため、表現を修正しました。 https://ruby-jp.slack.com/archives/CLWSHA76V/p1712030750871819
*1:https://rubykaigi.org/2024/sponsors/
*2:apiというそのままの名前のマイクロサービスがあります
*3:スタディサプリ小中高のKubernetesクラスタにおいて、40%近いリソースがapiに利用されていました
*4: 同等の機能は puma にもFork-Worker Cluster Mode として実験的に実装されています https://github.com/puma/puma/blob/2bfa23375c1000fdd9dc811f8dd3344dd238d3ac/docs/fork_worker.md
*5:https://github.com/rails/rails/pull/23125
*6:後述の通り、実はその時点のRubyにはpitchforkが正常に動かないようなバグがあり、その時点での導入はおそらく不可能でした
*7:リクルートはRubyKaigi 2023へPlatinum Sponsorとして協賛しました! https://rubykaigi.org/2023/sponsors/
*8:その後pitchforkのissueで「松本で会ったのを覚えています!」と言われて嬉しかったです
*9:SREチームに所属しています
*10:ちなみにGRPC.postfork_*は呼んだときに 条件を満たしているかチェックする機構があるので、どっちも呼んでエラーになった方は無視するという荒業があります