こんにちは、データチームの@masaki925 です。
昨年末にMLOps に関する記事を書きました。
今回はその続編で、レコメンドシステムのJenkins 部分をAI Platform Pipeline (以下AIP Pipeline) に置き換えた話です。
昨今では国内でもKubeflow Pipeline (以下KFP) 系の導入事例がいくつか出ており、特にZOZOテクノロジーズさんの記事は大変参考にさせていただきました。
今回の話では、まだまだパイプラインを使いこなすところまでは至っていないですが、 最初に導入するにあたっての迷いどころや躓きどころ、反省点など、1事例として紹介できればと思います。
想定読者は、前回同様MLOps 初心者向けとなります。
- これからMLOps をやっていきたい方
- ML ワークフローのパイプライン管理を始めたい方
- KFP を導入してみたいがコンポーネントなどの実装に必要な情報量が多くて二の足を踏んでしまっている方
TL;DR
- メイン処理(学習/推論) コードを「ファットコンポーネント」に閉じ込めてみたところ、トレードオフが発生した
- pro: Data Scientist (以下DS) とML Engineer (以下MLE) のインタフェース (以下I/F) の明確化に成功した
- con: コンポーネントに関連するKFP の強みを活かしきれなくなってしまった
- KFP の力を存分に引き出すため、メイン処理コードを各コンポーネントに分解するTFX などのスキルが必要
- メイン処理コードのコンポーネント化が恒久的に発生する作業なのかは未知数。でも誰かがやらなきゃ。。つづく
各種バージョン
AIP Pipeline (KFP): 1.4.1
$ pip list | grep kfp kfp 1.6.2 kfp-pipeline-spec 0.1.7 kfp-server-api 1.6.0
背景・経緯
DS とMLE のI/F を定めるのが難しい問題
まず、前回のシステム構成を再掲しておきます
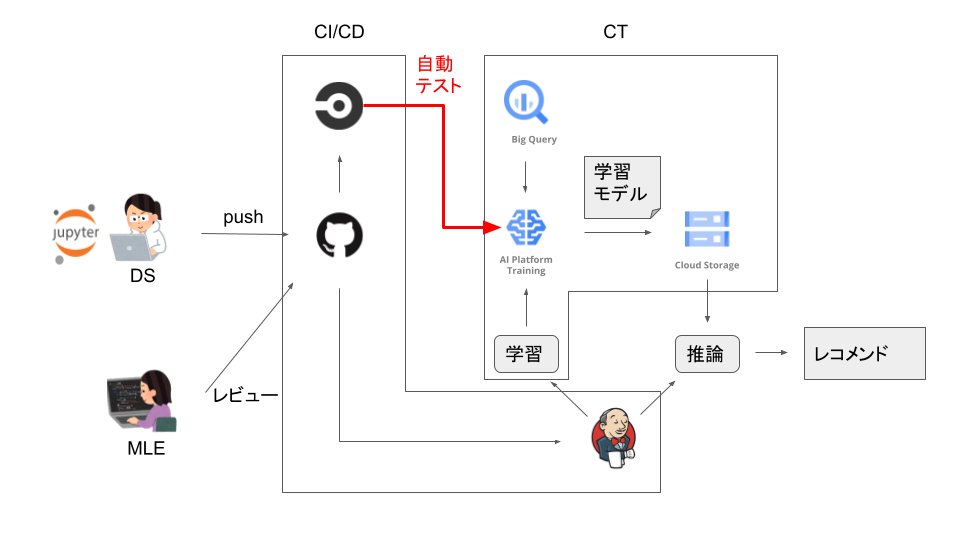
ここではDS とMLE*1 の管理領域が混ざってしまうことを課題と、 その解決策として「メイン処理コード*2のパイプライン化を(DS とMLE の)協業タスク化する」と書きました。
自分で書いておきながら、少しモヤっとする結論でした。
そんなモヤモヤを抱える中で、DeNA TechCon にて、Hekatoncheir の事例を拝見しました。
簡単に紹介すると、社内のML 案件をKaggle コンペに見立て、DS はコードとDockerfile をアップするだけで、後のプロダクション化は基盤側で吸収・対応するといった内容でした。
このキレイに割り切ったI/F に感心した筆者は、どうやらカスタムコンテナに希望がありそうだ、という認識を持ちました。
KFP の学習コスト高そう問題
一方、MLOps のレベルアップを目論んでいた筆者は、業務の10% ほどの時間を使いKFP のキャッチアップに勤しんでいました。
KFP のAIP 版sample を写経する中で、メイン処理コード (chicago_crime_trainer) はtar.gz でGCS にアップロードしてあるが、これを更新したい場合はどのようなフローになるのか?という疑問がありました。*3
また、GCP のリポジトリにあるAutoML を利用した例 では、コンポーネントが自作してあり、各ファイルの役割や構造を把握するのに苦労しました。
このあたりの感触から、最初はなるべくコンポーネントの自作などは避けて最小限でパイプラインを組みたい、という思いがありました。
ジョブ管理の技術選定、Vertex Pipelines は見送り
そうした中で、件のレコメンドシステムを別プロジェクトにも実装することになりました。
要件としてはバッチ2件(学習、オフライン推論) がスケジュール実行できればよいだけだったので、ジョブ管理システムとして何を採用するか、ゼロベースで検討を進めました。
Jenkins にある必要な機能(ロギング、スケジュール実行、再実行など) を損なうことなく、マネージドサービスがあり、MLOps の将来性が見込めるという理由でKFP を選定しました。
たまたま納期の1週間前に発表されたVertex Pipelines も検討しましたが、主にExitHandler (エラー時の通知用) が未対応という理由で断念しました。使おうとするとcompile エラーになります。 (kfp==1.6.2)
NotImplementedError: dsl.ExitHandler is not yet supported in KFP v2 compiler.
よって今回はKFP のマネージドサービスであるAIP Pipeline を採用しました。
やったこと
公開コンポーネントでカスタムコンテナ実行
メイン処理はコンテナ化しました。処理イメージは下記です。ログから学習モデルを作成し、モデルを使用してレコメンド結果をBQ に保存。いたって普通のプロセスです。
あとはBQ に保存されたレコメンド結果をWeb App が参照・利用しますが、そこは割愛します。
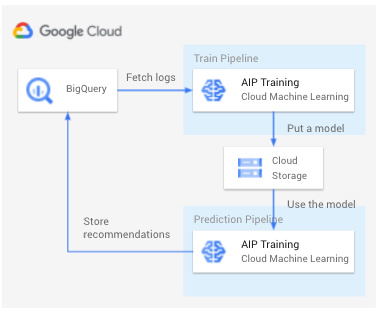
次に学習用パイプラインです。公開コンポーネントであるml_engine_op を使って、AIP Training でカスタムコンテナ実行をしています。
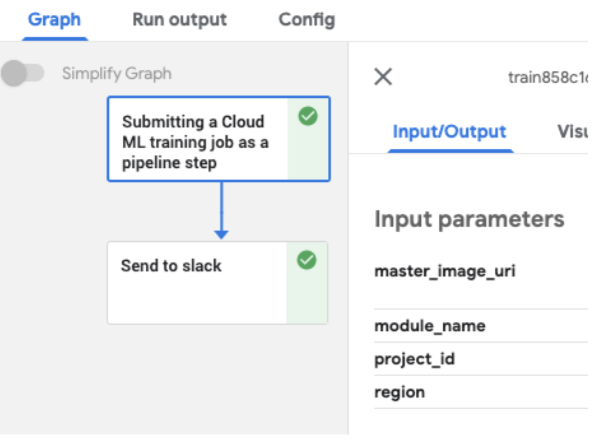
グラフを見てのとおり、メイン処理のコンポーネントが1つと、通知用のExit Handler があるのみです。
推論パイプラインも構成は同じです。
お察しの通り、これだけではパイプライン化する意味が無さそうです。
ファットコンポーネントと並列CI/CD
TFX 的には、学習データの取得や前処理、モデルのデプロイのためにコンポーネントを分けることが推奨されています。
ただ、今回は担当のDS がGCP の各サービスを使いこなすスキルを持っていたため、「AIP Training にsubmit さえできてしまえばあとは必要な処理はすべて完結する」状況ができていました。
加えて、DS がメイン処理、MLE がパイプラインの実装を担当するという役割分担(I/F) が良さそうという認識を持っていたこともあり、メイン処理を1つのコンポーネントに押し込める構成(ファットコンポーネント) を取りました。
こうした構成から、パイプライン全体でのCI/CD イメージは下記のようになりました。

メイン処理とパイプラインのコードはCI/CD のトリガーが分かれており、 それぞれが更新されたタイミングでデプロイされます。
パイプラインの引数には環境名(dev, prod など) のtag がついたDocker image のURI を取っており、メイン処理が新しくデプロイされてもパイプラインは気にせず動き続けます。 また検証用に新しくpush したメイン処理image を使いたい場合は、そのURI を渡してパイプラインを実行して試してみることも可能です。
メイン処理のCI ではAIP Training へのsubmit がsuccess することをtest によって担保していますが、AIP Pipeline と違って、Cloud Build では終了ステータスを拾うことができないため、自前でpolling 処理を挟んでいます。
polling script
SECONDS=0 TIMEOUT=3600 expected_state=SUCCEEDED failed_state=FAILED state=$(gcloud ai-platform jobs describe $1 2>/dev/null | grep state: | awk '{print $2}') while [[ $SECONDS -lt $TIMEOUT ]] do if [ "$state" == "$expected_state" ]; then echo "Job succeeded! All done!" break elif [ "$state" == "$failed_state" ]; then echo "Job failed! Please check the logs!" exit 1 else echo "Got $state :( Not done yet..." fi ((SECONDS++)) sleep 120 state=$(gcloud ai-platform jobs describe $1 2>/dev/null | grep state: | awk '{print $2}') done if [ $SECONDS -gt $TIMEOUT ]; then echo "TIMEOUT reached.." exit 1 fi
Cloud Build のtrigger はTerraform で管理されています (一部抜粋)
cloudbuild.yaml
steps: # Build - name: 'gcr.io/cloud-builders/docker' args: ['build', '-t', 'gcr.io/${PROJECT_ID}/trainer:${SHORT_SHA}', '-t', 'gcr.io/${PROJECT_ID}/trainer:${_ENV}', '.'] dir: 'recommend_task' # Push to Container Registry - name: 'gcr.io/cloud-builders/docker' args: ['push', 'gcr.io/${PROJECT_ID}/trainer:${SHORT_SHA}'] # Fix job name - name: 'bash' args: - -c - | echo create_cf_matrices_$(date +%Y%m%d_%H%M%S) > ${_CREATE_MATRICES_JOB_NAME_FILE} # Submit create matrices job to AIP Training - name: 'gcr.io/google.com/cloudsdktool/cloud-sdk' entrypoint: 'bash' args: - '-c' - | gcloud ai-platform jobs submit training $(cat ${_CREATE_MATRICES_JOB_NAME_FILE}) \ --master-image-uri='gcr.io/${PROJECT_ID}/trainer:${SHORT_SHA}' \ --region=${_REGION} \ -- \ -m trainer.create_cf_matrices_task \ --project-id=${PROJECT_ID} \ --matrices-bucket-name=${_BUCKET_NAME} # Polling the job status - name: 'gcr.io/google.com/cloudsdktool/cloud-sdk' dir: 'recommend_task' entrypoint: 'bash' args: - -c - | bash scripts/poll_job_status.sh $(cat ${_CREATE_MATRICES_JOB_NAME_FILE}) # Push image with env tag images: - 'gcr.io/${PROJECT_ID}/trainer:${_ENV}'
メイン処理用trigger
resource "google_cloudbuild_trigger" "build-recommend-task" { name = "build-recommend-task" github { owner = "quipper" name = "a_great_recommend_system" pull_request { branch = "main" } } filename = "recommend_task/cloudbuild_dev.yaml" included_files = ["recommend_task/**"] substitutions = { _ENV = "dev" } }
hacky なRecurring Run へのpipeline version の反映
スケジュール実行にはRecurring Run を利用しました。
が、後述しますが、次回やるならCloud Scheduler + Pub/Sub にすると思います。
Recurring Run (kubeflow 内部ではJob という単位で登録されています) を登録する(create_recurring_run) ための引数として、pipeline id もしくはpipeline version id を指定する必要があります。
pipeline version id を指定しない場合は、pipeline のdefault version が利用されます。
このdefault version というのが曲者で、少なくともKFP SDK CLI でパイプラインを更新(kfp.Client.upload_pipeline_version) した場合は、一番最後のversion がdefault として選択されます。
これだと、うっかり意図しないパイプライン実行が走ってしまう可能性があるため、なるべくversion まで指定したJob が作成したくなります。
image tag と同様、環境名でversion を固定できればよかったですが、KFP の仕様としてそれはできません。version 名はユニークである必要があります。
Note: ... Pipeline version names need to be unique within each pipeline.
そうなると既存のJob をupdate したくなりますが、KFP SDK のドキュメント を見る限りupdate メソッドはありません。なので新しいversion で新しくJob を登録すると同時に、既存のJob をdisable または削除しないと、重複して実行が走ってしまうことになります。
今回は、デプロイの際に都度古いJob を削除するようにしました。
少しhacky ですが、こうなりました。 (name からid の取得も地味に面倒)
def __experiment_id_from_name(self, e_name: str) -> str: e = self.client.get_experiment(experiment_name=e_name) return e.id def __version_id_from_name(self, p_id: str, v_name: str) -> str: # NOTE: Since kfp Client doesn't have an API to get a specific version from version name, # we need to find it from the version list. # It assumes that at least latest 10 versions include specified version name. v_list = self.client.list_pipeline_versions(p_id, page_size=10, sort_by="created_at desc") _versions = [v for v in v_list.versions if v.name == v_name] if not _versions: raise(Exception(f'the specified version name: {v_name} is not found.')) return _versions[0].id def delete_recurring_runs(self, exp_id) -> None: # NOTE: Its a kind of private property but kfp.Client doesn't have that feature for now. job_api = self.client._job_api # FIXME: use filter: https://github.com/kubeflow/pipelines/issues/4954 j_list = job_api.list_jobs(page_size=10, sort_by="created_at desc") jobs = [] for j in j_list.jobs: for r_ref in j.resource_references: if r_ref.key.type == 'EXPERIMENT' and r_ref.key.id == exp_id: jobs.append(j) break for j in jobs: job_api.delete_job(j.id) j_list = job_api.list_jobs(page_size=10, sort_by="created_at desc") def renew_recurring_run(self, pipeline_name: str, module_name: str, version_name: str, cron: str, image_uri: str) -> None: pipeline_id = self.client.get_pipeline_id(pipeline_name) e_name = module_name exp_id = self.__experiment_id_from_name(e_name) ver_id = self.__version_id_from_name(pipeline_id, version_name) self.delete_recurring_runs(exp_id) r_run = self.client.create_recurring_run( experiment_id=exp_id, job_name=f'{pipeline_name}_{version_name}', pipeline_id=pipeline_id, version_id=ver_id, cron_expression=cron, max_concurrency=1, no_catchup=True, params={ 'master_image_uri': image_uri, 'module_name': module_name, } )
Slack 通知は自作コンポーネント
これはくやしいのですが、ExitHandler でstatus によって通知内容を変更させたいとなったときに、Argo 変数の展開タイミングの都合でコンポーネントが必要になります。
下記のようにstatus を渡し、コンポーネントの中でstatus によって分岐しています。
send_to_slack_task = send_to_slack_op(
webhook_url=slack_webhook_url,
status='{{workflow.status}}',
title=f'{PIPELINE_NAME}',
link=f'{kfp_endpoint}/#/runs/details/' + '{{workflow.uid}}',
)
with dsl.ExitHandler(send_to_slack_task):
train_task
Airflow のようにon_success_callback やon_failure_callback があればこんなことはしなくて済むことを考えると、単純なワークフローエンジンとしての機能はやはり弱いのかなと思います。
ML ワークフローならではの機能を活用して初めて旨味があります。
やってみた感想・ふりかえり
DS とMLE のI/F の明確化と、作業の並行化に成功した
よかったこととして、メイン処理code の変更をGCR のimage tag で管理することで、DS の作業とMLE の作業を分離・並列化することに成功しました。
実際に、開発途中で仕様変更(BQ に追加するカラムの変更など) がありましたが、パイプライン側では一切気にすることなく進めることができました。
コンポーネントに関するKFP の強みが活かせていない
一方で、KFP の強みであるPipeline Metrics やVisualization 機能などは使えていません。
せっかくMLOps の将来性に賭けてKFP を選定し、TFDV やTFMA を使ってあんなこと やこんなこと がしたいのに、これでは意味がありません。
これらを活用するためには、コンポーネントを更に分解し、自前でデータをコンポーネントの出力を各機能に合わせて整形・処理するか、TFX ライブラリなどを利用して必要なOutput やMeta Data をKFP に認識させる必要があります。
そう思って少しTFX STANDARD COMPONENTS を覗いてみると、やはり学習コストが高そうに感じてしまいます。
DS でもないMLE でもない、TFX エンジニアというロールがあるのではないかとも思えてきます。*4
噂によると、Fairing やKale というツールが自動でNotebook からコンポーネント化できるツールもあるようなので、そのあたりも踏まえて引き続き調査・検討していきたいです。
コンポーネント化を見据えたPub/Sub トリガー
Recurring Run はJob の取り扱いが面倒なことに加えて、 上記のようにコンポーネント化が進んで来ると、スケジュール以外での実行トリガーが欲しくなる可能性があります。
データの傾向変化やモデルの精度変化をトリガーにしたいとなった場合に、Pub/Sub のほうがより柔軟に制御できそうです。
Vertex Pipelines のスケジュール実行 も、ドキュメントに紹介されている手順を踏むとCloud Scheduler + Pub/Sub + Cloud Function の構成が作成されるので、おそらくその意図があるのではないでしょうか。
そうなると、今回hacky だったversion の更新も、Cloud Function にデプロイする際の環境変数で取り扱うことでシンプルになりそうです。
まとめ
前回同様、筆者のようにMLOps 専任チームが無く、まずはシンプルにパイプラインの運用を始めてみたい、という方には、公開コンポーネント + カスタムコンテナで短いパイプラインを組んでみるのは「慣れ」るのに良いと思います。
ただ、各種ツールの機能を有効活用するためには、コンポーネント化のスキルを身につける必要がありそうです。
TFX が体系化したようにパイプラインの各ステップの種類は限られるので一度TFX コンポーネント化してしまえば汎用的に使い回せるのか、 メイン処理によって内容が変わってくるためやはりDS もMLE もそれぞれがキャッチアップしなければいけない領域なのか、まだ不明です。
今後も良いやり方を模索していきたいと思います。
データチームでは絶賛仲間を募集中のため、もし本記事の内容に少しでも興味を持たれた方は、下記のリンクからぜひエントリーしてみてください。
https://www.saiyo-dr.jp/recruit/Entry/select_job.do?to=job_view&jobId=1078