RAGを使った社内ドキュメント検索Botの構築
こんにちは!スタディサプリのSREをしている@_a0iです。みなさん、生成AI使っていますか〜!? ChatGPT, Graffer AI Studio, Microsoft Copilotなど企業で使える生成AIはさまざまだと思います。 しかし、仕事で生成AIを使う際にこれらでは物足りないと思うことはありませんか?一般的な回答ではなく、仕事に特化した回答を生成してほしい、そう思ったことはないでしょうか。
今回Retrieval-Augmented Generation(通称RAG)を使って社内のドキュメントを自然言語で検索できるSlack botを作ってみました。この記事ではそのプロジェクトの背景、システム構成、工夫ポイント、効果と課題について紹介します。
背景
SREは日々アプリケーション運用環境を幅広く見ている関係上、開発者の方々から様々な問合せを受けます。これらの問い合わせの答えが載っているドキュメントもありますが、スタディサプリの開発現場では以下の問題を抱えています
- ドキュメントの保存場所が散らばっているため、適切な検索場所を見つけるのが難しい
- 英語を使用している開発メンバーもいるため、ドキュメントは日英言語混じっている
これらを解決するための統一的インターフェースがあると便利ではないかという話が以前からチーム内であがっていました。 これに対してRAGを用いることで、Slackという既存の共通インターフェースを利用して自然言語で簡単にドキュメントを検索できるのではないかと思い、検証をはじめました。 また、相手が人間であることで問い合わせを遠慮するようなケースでも、bot相手であればより問い合わせやすく開発者の生産性があがるのではという効果も狙っています。
RAGとは
RAGは、Retrieval-Augmented Generationの略で、情報検索システムと生成AIを組み合わせた新しいアプローチです。RAGでは、まず検索エンジンによって関連するドキュメントを検索し、その結果を元に生成AIが回答を生成します。このアプローチにより、従来の検索エンジンと生成AIの長所を組み合わせ、より精度の高い情報提供が可能となります。
システム構成
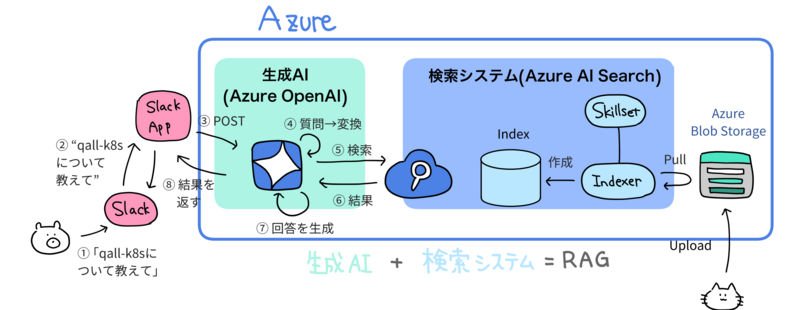
私たちのサービス開発インフラとしてAWSをメインで使用していますが、リクルートのAI活用指針*1に基づいてツールを選定し、Azureを利用しています。 図に示している通り、社内ドキュメント検索におけるRAGは生成AIに検索システムを組み合わせたシステム構成となっています。
それぞれの役割について簡単に説明します。
検索システム:
- Azure AI Search
- インデックス作成、検索クエリの実行などを行う
- インデックスのデータソースにはAzure Blob Storageを使用
- Azure AI Search
生成AI:
- Azure OpenAI On Your Data
- 検索クエリの生成、検索システムの検索結果を元に回答を生成
- Azure OpenAI On Your Data
検索Bot:
- ユーザーインターフェースの設計(チャット形式での問い合わせ対応)
- RAGと連携させ、ユーザーの問い合わせに対する最適な回答を生成
ユーザーがbotに問い合わせをすると、①〜⑧に書かれている順番でこれらのシステムが動作します。
① ユーザーがSlack botに問い合わせをする
「qall-k8s」とは社内で使っているツールの名前で、ツールの詳細は社内に存在するドキュメントにしか記載されていません。そのため、ユーザーは「qall-k8s」に関する情報を知りたいと問い合わせます。
② SlackからSlack Appに問い合わせ内容が送信される
③ Slack AppがAzure OpenAIに問い合わせ内容と検索対象Indexを含めてPOSTする
④ Azure OpenAIが問い合わせ内容を受け取り、検索システムに投げるクエリに変換する
⑤ Azure OpenAIがAzure AI Searchに検索クエリを投げる
⑥ Azure AI Searchが内部で保持しているIndexを検索し、検索結果が返る
⑦ Azure OpenAIが回答文を生成する
⑧ Slack Appを経由してSlackのbotが回答をポストする
図に示している通り、社内ドキュメント検索におけるRAGは生成AIに検索システムを組み合わせたシステム構成となっています。
詳細な説明
検索システム
ここではドキュメントから検索インデックスを作成する流れについて説明します。

- Azure Blob Storageにファイルをアップロード
- IndexerがAzure Blob Storageからファイルを取り込む
- カスタムスキルが実行され、取り込んだドキュメントの本文をチャンク化し、チャンクを埋め込みベクトル化する
- 検索Indexが作成される 1と2,3,4は非同期で実行されることに注意してください。
これらはAzure AI Searchの機能としてUI上から簡単にぽちぽちできます。簡単ですね。

ではそれぞれ説明していきます。
1 Azure Blob Storageにファイルをアップロード
Azure Blob Storageにファイルをアップロードする方法は、今の所手作業で行なっています。AzureのCLIを使ってローカルマシンからファイルをアップロードします。
2 IndexerがAzure Blob Storageからファイルを取り込む
Azure AI SearchのIndexerは、クラウドデータソースからテキストデータを抽出し、ソースデータと検索インデックスの間でフィールド間のマッピングを使用して検索Indexを作成するクローラーです。(ref. Indexers in Azure AI Search)
また、検索Indexは検索性能向上のために作られるものです。検索システムに触れたことがない方はこのIndexerやIndexを初めてきくかもしれません(Databaseにも似たような概念がありますね)。
Indexerは単にクローリングを行うだけではなく、途中様々な"技"を実行することができます。
その"技"とは...次で説明します。
3 カスタムスキルが実行され、取り込んだドキュメントの本文チャンク化し、チャンクを埋め込みベクトル化する
個人的にここが理解しづらいポイントだったので、一つ一つ丁寧に説明していきます。
カスタムスキルとは
Azure AI Searchには様々なカスタムスキルが定義されており、選択するスキルによってデータソースに"技"を加えることができます。
スキルセットを自分で定義することもできますが、組み込みのものもあります。
組み込みのスキルセットにはたとえば「画像分析」であったり、「テキスト翻訳」があります。
データソースそのままを検索可能にするのでは不十分な事例がありそうだなと想像つくのではないでしょうか。
私たちはカスタムスキルを利用して以下を実行しています。
- チャンク分割
- 埋め込みベクトル化
チャンク分割
検索ではデータソースの中身を「チャンク」に分割してインデックスに格納することができます。
チャンクを分割することでいくつかのメリットがあります。
- 検索精度の向上
- トークン消費量の調整
1つのでかいドキュメントをそのままインデックス化すると、何を検索してもそのドキュメントが引っかかってきてしまうという問題があります。
1つのチャンクに色々な情報が含まれていれば、当然様々な検索ワードに対してそのチャンクがヒットします。しかし、余計な情報が含まれており検索精度が下がります。
また、生成AIのモデルごとに1度に利用できるトークン*2量が決まっています。トークン量の制限に合わせてチャンク分割をする必要があるという理由もあります。
埋め込みベクトル化
検索には色々な手法がありますが、私たちはベクトル検索とフルテキスト検索のハイブリッド検索を使っています。
ベクトル検索を行うためには取り込んだテキストデータをベクトル化する必要があり、スキルセットを使って簡単にベクトル化を行なっています。
長くなるのでここでは「ベクトル検索」「フルテキスト検索」「ハイブリッド検索」の説明は行いません。
気になる方は公式ドキュメントを参照してください。
データソースの準備
検索する元となるデータを準備する必要があります。社内のドキュメント内を検索したいため、ここが一つポイントとなります。
データソースにはデータベースなども指定可能ですが、私たちはひとまずドキュメントを検索できるようにしたかったため、Azure Blob Storageを使用しました。
Azure Blob Storageは、大容量の非構造化データを保存するためのクラウドストレージサービスです。bot(RAGシステム)開発者がローカルPCを経由してAzure Blob Storageにドキュメントをアップロードすることで、検索対象となるドキュメントを準備しました。
データソースには社内ドキュメントページのもととなるMarkdown形式のファイルのみならず、GitHubに保存されている特定のissueも含めています。
生成AIシステムの構築
生成AIシステムにはAzure OpenAIを使用しました。Azure OpenAIは、生成AIを利用するためのAPIを提供しており、RAGのような生成AIを用いたシステムを構築するのに適しています。
私たちはChat Completions APIを使用し、ユーザーの問い合わせに対する回答を生成する処理を実装しました。Chat Completions APIはチャットに特化したモデルとなっており、事前にロールを設定しておくことでより望ましい結果を得られるようにしています。
工夫ポイント
ハルシネーション対策
生成AIには「ハルシネーション(和訳:幻覚)」と言われる現象が発生することがあり、存在しない回答を返すことがあります。私たちはこの対策として、回答には必ずソースドキュメントへのリンクを含めることでユーザーに正しい回答かどうか確認する術を提供することにしました。
技術的にはソースドキュメントのメタデータにURLを含めるようにしました。インデクシングの過程でこのメタデータがチャンクに含まれるようになり、Slackのbotが回答に含めてくれます。
検索精度を一定に保つ
社内のドキュメントは数限りなく存在しますが、現状一部ドキュメントに限定しています。これには以下の理由があります。
- 一般にドキュメントを増やせば増やすほど検索精度が下がると言われている
- 古いドキュメントが混在することで、新しく正しい情報よりも古くなってしまった情報が検索結果に返されてしまうことを防ぐ
効果
botを利用するユーザーが増え、徐々にその効果を発揮しつつあります。
また、botにより「精度の高い検索結果を返して欲しい」という要求に伴い、社内ではより質の高いドキュメントを書くモチベーションが高まっています。
課題
うまく行っているように見えますが、いくつか課題が残っています
- 英語のドキュメントに関する課題の解決はできていない
- ドキュメント追加及びインデクシングが手動のため、手間がかかる
- 同じドキュメントに対してチャンクが重複して登録されてしまうケースがあるが、原因調査中
まとめ
以上、社内のドキュメントを検索する簡単なRAGを使ったシステムの説明でした。
まだまだ課題は多いものの、単にbotの利便性を享受できるだけではなく、ドキュメント改善のきっかけになるとは思っていませんでした。
ゆくゆくはドキュメント検索だけではなく、SREの代わりに開発者の伴走をしてくれるようなトラブルシューティングもできるbotを目指していきたいと考えています。
今後の活動をお楽しみに!